|

NetKernel News Volume 2 Issue 33
June 17th 2011
What's new this week?
- Repository Updates
- DropBox nCoDE Demo - Part 3
- On Metadata
- How Metadata is Usually Described
- About "about"
- Metadata as Resource
- A Resource Oriented Definition of Metadata
- The Purpose of Metadata
- What's Metadata Good For? And Other Dumb Questions
- Contextual Association
- Attributes
- Response Associated
- Parameterised META Resources
- Extrinsic Metadata Resources
- Mono-Spacial Systems: Semantic Web
- General multi-spacial ROC systems
- Power of the Extrinsic Metadata Resource model
- Corollary: The Search Giant's versus RDFa
- Euro-Bootcamp
Catch up on last week's news here
Repository Updates
There are no updates this week. Steady as you go.
DropBox nCoDE Demo - Part 3
Tony concludes his nCoDE Dropbox demo with details of the OAuth client credential exchange...
http://durablescope.blogspot.com/2011/06/dropbox-with-ncode-part-3.html
On Metadata

Its time for me to face my demons. Its time to discuss metadata.
Strange choice of introductions? Well metadata and I have had a somewhat schizophrenic relationship.
Back in the day (late 90's) I was in the same HP research laboratory as the Jena semantic web team. The problem, for me, was that I wouldn't/couldn't drink the cool aid - I kept my distance - forming an independent team to begin the ground work on ROC. This was not the easy path.
On reflection I now understand why I held out. I can now see, now that we've worked out the ROC abstraction, that there was still so much about the Web that was not understood - especially the progression from the single address space of the Web to the general contextual resource spaces of ROC. And, especially the practical consequences for the engineering of the solutions.
I'm interested in making things that work, and work really well. It felt like we needed to really understand the first order problem of engineering resource oriented systems - the second order metadata could wait...
...so lets just say the Jena team and I did not see eye to eye and leave it at that.
Maybe this history left me with some mental scars, but I have a certain wariness about putting the cart of metadata before the horse of systems engineering.
But, as Florence and her machine would say, the dog days are over. Time to face up to metadata and coolly stare each other in the eye.
I think that we are now on very solid ground with ROC. Which allows us to fully consider metadata from the perspective of the general ROC abstraction.
I know that we have many metadata patterns in the ROC domain that are yielding daily practical benefits but I think that a clear articulation will help drive even more possibilities. I also believe that a general ROC perspective on metadata can offer feedback into the special case of the single address space case of the World Wide Web. So here goes...
How Metadata is Usually Described
We probably all know that Metadata is data about data. Look at, for example, the wikipedia entry...
http://en.wikipedia.org/wiki/Metadata
Here's another perspective, from NISO, with the friendly sounding title "Understanding Metadata"...
http://www.niso.org/publications/press/UnderstandingMetadata.pdf
The opening paragraphs of which go like this...
What Is Metadata?Metadata is structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use, or manage an information resource. Metadata is often called data about data or information about information. The term metadata is used differently in different communities. Some use it to refer to machine understandable information, while others use it only for records that describe electronic resources. In the library environment, metadata is commonly used for any formal scheme of resource description, applying to any type of object, digital or non-digital. [abbreviated] There are three main types of metadata:
|
But it has always worried me that there are some pretty vague concepts here which rapidly lead to cans of worms, with many perspectives and interpretations.
I think the problem has been, as far as I've ever seen, that there are implicit assumptions that are not articulated.
As I'll show, I think we can use our ROC perspective to get back to first principles and give ourselves some more solid ground to build on.
About "about"

The root cause of trouble in the standard definition of metadata as "data about data" is that little word in the middle: "about".
About tells us nothing, and yet implies too much.
For example, the standard definition completely fails to address identity. If something is information "about" some other thing, does it implicitly mean that the meta-information has within it the identifier of the data which it is "about"?
Sometimes perhaps, but as we'll see, it certainly doesn't have to.
So while "data about data" is easy to say, its pretty lazy. It is context free and abrogates responsibility for the fundamentals of the relationship between information and identity.
However this is precisely what ROC provides as a well defined foundation. It is a working and highly efficient, practical system that provides the basis within which identity and context form the information system. So it feels like ROC ought to be able to provide a more solid statement of what metadata is.
I think we can do a lot better than "about".
Metadata as Resource
Lets take the ROC axioms, defined in the first section of our Introduction to ROC whitepaper, as the basis for a definition of Metadata.
In summary, the principles of resource-oriented computing are:
- A resource is an abstract set of information
- Each resource may be identified by one or more logical identifiers
- A logical identifier may be resolved within an information-context to a physical resource-representation
- Computation is the reification of a resource to a physical resource-representation
- Resource representations are immutable
- Transreption is the isomorphic lossless transformation of one resource-representation to another
- Computational results are resources and are identified within an address space
Incidentally I noticed that this whitepaper* is now getting a little long in the tooth. Its main points are all still valid and correct but it refers to NK3 and it needs to explain the detail behind axiom #3 of relativistic contextual spacial relationships embodied in NetKernel 4 - one day I'll get to it!
A Resource Oriented Definition of Metadata

With the ROC axioms in mind, a general ROC definition of Metadata is...
Metadata is a resource contextually associated with a resource
The key here is "contextually associated with" - where "contextually" immediately states that a metadata resource furnishes the associated resource with context. But, as we shall explore in detail in a moment, it also applies to the contextual nature of the association. Recall that in ROC "contextual" elicits the rich interplay between identity and structured address spaces (plural).
But first lets see what simply changing "data" to "resource" does for us, by referring to the ROC axioms.
From Axiom #1 we already know what a resource is. Its an abstract set of information. So metadata is an abstract set of information contextually associated with another abstract set of information.
From Axiom #2 it follows that a metadata resource may have one or more identifiers.
From Axiom #3 a metadata resource's identifier may be resolved in an information context to a physical representation. By which we mean that metadata may be requested and resolved.
From Axiom #4 we know that it takes computation to make metadata concrete. As we'll see this computation cost might be pre-paid (ahead of time) or it may be deferred and computed just-in-time. But it is always there. (This explains why adding metadata to a system always takes time/money - you've got to pay the piper)
We'll take it as read that Axiom #5 is a "good thing" - for the same reasons as for any resource - its share and share alike in ROC, so don't go modifying representation state in a concurrent system.
Transreption, defined by Axiom #6, is actually saying that there is no "one-true" representational form for any resource. It follows that there is no one representational form for metadata. I'm pleased about this - since, as you saw with the first section, the classical definitions of metadata almost instantly descend into the minutia and proliferation of formats and then rapidly diverge from there. But, with a Resource Oriented perspective, we are forced to step outside of the representational form and accept that it is (fundamentally) irrelevant - and as we'll see, there are bigger fish to fry.
Axiom #7 says that a metadata resource once computed may have its own resource identifier just as any other resource. We'll see that this allows us to formally understand the notions of implicit and approximate identity. (Amongst other things, "approximate identity" is what we use when we search for resources)
Axioms
I suppose with this definition we have just introduced a new axiom to ROC, and there then follows an immediate requirement for a further axiom...
- Metadata is a resource contextually associated with a resource.
- A resource may have any number of independent contextually associated metadata resources.
We'll see how #9 is needed later.
The Purpose of Metadata
Just as with the physical world and magnetic monopoles, it is a pretty rare thing to use a "Metadatum" - ie an individual isolated metadata resource.
Usually, we encounter metadata collectively. For example, the index of a book or table of contents. The reason for this is that...
The value and utility of Metadata increases when it is aggregated.
A very practical everyday example of this is, we save time finding stuff we're interested in by looking in an index, and an index has more value the more entries it has (imagine if the index of a book only had one entry).
So how can we understand this from the ROC perspective?
Well if metadata is a resource, then it's a set. Therefore an aggregation of metadata is a superset: the set of all metadata-sets.
At any given moment, "stuff that is interesting to us" is also a resource, one consisting of a sub-set of the aggregate set.
By applying constraints and/or transformations we can partition the aggregate set into a sub-set which satisfies our criteria. And, since our definition requires that metadata has a "contextual association", then from the constrained subset we must be able to resolve the resource. Therefore the constrained sub-set offers a context from which we can interact with the primary resources.
That, in a very concise way, explains what a Google, Yahoo or a Bing internet search engine is. It is an aggregate metadata resource set with the ability for us to apply selective constraint in order to reveal the identities (links) to bits of the web that interest us.
But sub-setting the aggregate set is not confined to "search" applications. For example if we're an access control architecture layer, the "thing that is of interest to us" is the set of resources for which suitable access credentials have been supplied. For a unit test system, it is the set of resources expressing unit test declarations. etc etc
OK, for completeness, lets apply our formal ROC axioms:
An aggregate metadata set is also a resource (by Axiom #7). Constraining the set to a sub-set is a transformation requiring computation (Axiom #5) and the subset is another resource (Axiom #7).
From this formal view, we now very clearly understand why the phrase "one person's metadata is another person's data" is a truism. The sub-setted aggregate resource is also a resource.
But it doesn't have to stop there, if it too is a resource then it too may have its own contextually associated metadata resources ... and so it goes, ad infinitum...
Notice that this discussion treats metadata resources in the abstract - we have had no need to concern ourselves with Axiom #6 and representation form. (We'll get on to "contextual association" soon I promise).
What's Metadata Good For? And Other Dumb Questions
What's Metadata good for? Are there really 3-types of metadata, as categorised by NISO?
To the first: Errrr, anything which when aggregated has value in the context of your information solution. To the second: of course not, after the careful definition given above, its clear there are literally an infinite number of potential associated supersets and to classify them would be impossible. To see this just ask the rhetorical question "How many types of information resource are there?".
Comparative Example

One of my favourite analogies when thinking about metadata in software systems is to compare the WSDL specification of a SOAP web-service (take your pick they're all as depressingly bad as each other) with that of a mature metadata driven industry such as discrete electronic components.
Here, for example, is the National Semiconductor datasheet for its LM741 op-amp (the op-amp is the most common-or-garden component you can get and every manufacture offers a "741" device - its the "Hello World" of components)...
http://www.national.com/ds/LM/LM741.pdf
The 741 is a very simple and universal device and yet it still has a very detailed and rich specification sheet. Different engineering design decisions and requirements will dictate which subsets of this metadata are useful in any given context.
Notice its an aggregate resource - the composition of many different metadata resources.
Notice that it doesn't actually tell you what a 741 op-amp does, aside from a cursory memory-jogging "example circuit". You, as a trained electrical engineer are assumed to know not to connect OUTPUT to V+ in a positive feedback loop. The specsheet is pure metadata.
Notice something else, electrical engineering metadata is principally a human-readable resource. There will undoubtedly be a downloadable machine-readable SPICE simulation of the device somewhere - but the questions that matter in engineering are very often much more complex than the simple interface definition and electrical operating constraints of a CAD model (the equivalent of WSDL) - even for something as simple and ubiquitous as the humble 741.
The reason for this is that large scale systems always have more than one solution and require a delicate balance of compromises to be struck. (See my previous newsletter on why its called the "Art of Electronics"). Metadata helps the engineer find the best overall system balance to meet their given design brief.
(Oh how I wept when they came out with WSDL and yet they had the entire richness of the Web client-server browser model to provide rich human-readable engineering information about services. What does it do? How will it perform? When's it available? Where do I get credentials? Who do I call when it goes wrong? Such basic dumb questions need basic dumb answers... Oh! Web Services thow art tragedy. Tragedy!)
Metadata In Software Engineering
I won't attempt to make the category error of offering a general categorization! But in NetKernel we already use metadata resources to meet the following software engineering requirements...
- Specification
- Description
- Utility
- Functional Equivalence Comparison
- General Design Intent / Purpose
- Performance Expectation
- Logging
- Qualitative Comparison of Architectures
- Statistical Operational Characteristics
- Testing
- Structural Constraints
- semantic Constraints (small-s - see below)
- Contractual Operational Constraints
- Trust and Trust Boundaries (aka Security)
- Dynamic Configuration
- Operational management
I'm going to keep with the specifics of NetKernel for the next section - since as the first (only) general ROC system it concretely allows us to explore the ways in which "contextual association" can be understood.
However I hope it will be apparent that the patterns which are discussed are general and are applicable more generally in extended architectures.
Contextual Association

The unarticulated, but necessary, implication of "about" in the previous definitions of metadata is that the information in the metadata resource must "somehow" be related to some other information.
In ROC we understand that this must mean that the metadata resource either explicitly references an identity of the resource or, possibly, implicitly provides sufficient breadcrumbs to be able to reconstruct an identity.
We shall see that this is richer than simply direct or indirect use of a resource identifier, we are able to include the "locality" of the scope of the ROC spacial architecture as a factor in ensuring the contextual association is meaningful. We are also able to allow that a resource may have one or many identifiers (Axiom #2).
Here we'll consider and define the manner in which "contextual association" can be implemented and consider the significance of patterns using both explicit or implicit identity for the associated resource.
As an example, notice in the 741 op-amp datasheet the liberal scattering of Order Number LM741H etc - these are explicit identifiers of the part number to put on your purchase order which will "reify a representation".
So lets look at the possible ways of enabling the contextual association of metadata resources, and lets take them in-order of "relative locality", most localized first...
Attributes
A completely localized approach to associating metadata with a resource is to "decorate" the primary resource with attributes. That is, the resource itself contains embedded metadata which can be independently parsed and extracted from it by an aggregator.
A key constraint of this model is that metadata attributes must be "out-of-band"; that is, the primary information of the resource is unperturbed by the addition of the metadata.
The introduction in Java 5 of Annotations is a localized attribute-based metadata model.
Equally, the RDFa W3C standard enables RDF metadata to be expressed as attributes embedded within an HTML/XHTML resource.
In both cases it is not necessary for the creator of the metadata to explicitly state the identity of the resource to which the metadata is associated. The localized context of the attribute is sufficient for an aggregator to infer the identity of the resource in question, and even, for example in the case of RDFa, metadata associated with the identity of another referenced resource.
The advantage of the attribute model is that it is relatively simple to augment a resource with metadata.
However, a considerable draw back, if you accept the premise of Axiom #9 (introduced above), is that our general ROC expectation is that when metadata is a resource then inevitably any given resource will be associated with more than one metadata resource. Therefore cramming different attribute models into one resource would mean that things will get messy very quickly.
A further drawback is that an attribute based model can only work with a strict representation model for the resource. It cannot cope with Axiom #6 whereby a resource is abstract and representations may take unlimited form. Transreption does not (cannot) promise to isomorphically preserve attribute metadata.
However, as we see with RDFa and HTML resources - these trade trade-offs have been deemed acceptable, and the HTML resource representation so common, that the limitations of the approach are a price worth paying for the anticipated benefit of having a simple model for web content to be augmented with metadata resources.
NetKernel - NetKernel does not implement an attribute based metadata model in the standard modules' endpoint declarations. However the standard and active grammar specifications allow attribute metadata to describe the nature of arguments, and this shows up in the boilerplate documentation for every endpoint. But, just as with the Web, you may readily adopt the attribute model within any resource representation you produce in a NetKernel solution.
Response Associated
Any resource provider may supply arbitrary and unlimited metadata as secondary state conveyed in parallel with the response to a request for the resource. The most obvious example of this approach is mimetypes (both in HTTP and email systems), another is the SOAP message header.
By definition, since you must request it before you even access the metadata, the identity with which the metadata resource is associated is known and so may be explicitly incorporated with any metadata aggregation.
The drawback of this model is that the provider of the resource must be tightly bound to the metadata and therefore must be reimplemented if new or additional metadata resources are to be associated - again causing friction with our expectations from Axiom #9.
Furthermore the metadata resource is "out-of-band" to the resource oriented domain. It follows that an aggregator must, ahead of time, be able to discover and request (compute, Axiom #4) every resource in every address space in an information system in order to present any accumulated aggregate metadata driven services.
As with attributes this model is not guaranteed to survive axiom #6.
NetKernel - you can easily implement this model in a NetKernel solution. The INKFResponse object provides a convenience method to specify mimetype, but more generally it allows arbitrary response headers to be specified on a response (mimetype is also just a header, it only has a setter method for convenience, since HTTP applications almost always need the mimetype to be specified). Attached metadata headers would use a common convention to name the header so that it is detected by an aggregator. Furthermore the mapper allows arbitrary response metadata to be declaratively defined and associated with any request to a mapped logical endpoint - so unlike with SOAP, you can externally decorate a resource set's representations with metadata at runtime.
Parameterised META Resources
An endpoint in an ROC system should respond to a META request. The response is a set of parameterized metadata resources specific to that endpoint. Typically the META request is issued for the identifier of the endpoint - not an identifier of a member of the resource set managed by the endpoint. As such it is a direct request for the metadata about the endpoint and not about the endpoint's resources. Although clearly often there is a close relationship between the two.
Here for example is how to request the META resource of the Groovy language runtime (id: GroovyRuntime) using the request trace tool...
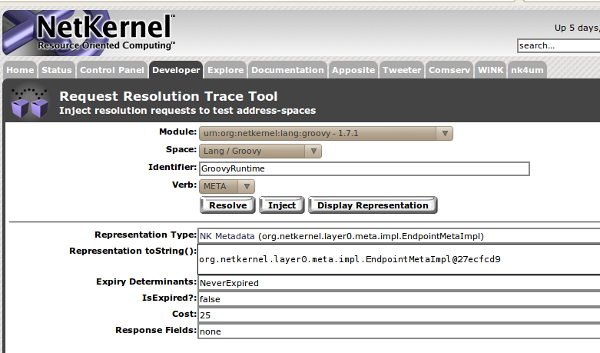
Which results in the following metadata resource (transrepted to an XML serialized HDS structure)...
<name>Groovy</name>
<desc>Groovy language runtime</desc>
<icon>res:/org/netkernel/lang/groovy/img/icon.png</icon>
<fields />
<class>org.netkernel.layer0.meta.IEndpointMeta</class>
<identifier>GroovyRuntime</identifier>
<interface>
<verbs>
<verb>SOURCE</verb>
<verb>SINK</verb>
<verb>EXISTS</verb>
<verb>DELETE</verb>
<verb>NEW</verb>
</verbs>
<grammar>
<group>
<group name="scheme">active</group>:
<group name="activeType">groovy</group>
<interleave>
<group>+operator@
<group name="operator">
<regex type="active-escaped-uri-loose" />
</group>
</group>
<group min="0" max="*">+
<group name="argName">
<regex type="nmtoken" />
</group>@
<group name="argValue">
<regex type="active-escaped-uri-loose" />
</group>
</group>
</interleave>
</group>
</grammar>
<args>
<arg>
<name>operator</name>
<desc>Groovy program to be executed</desc>
<fields />
<type>REPRESENTATION</type>
<reps>
<rep>
<hash>VP/P/GroovyCompiledRepresentation</hash>
<name>CompiledGroovyRep</name>
<class>org.netkernel.lang.groovy.representation.CompiledGroovyRep</class>
</rep>
</reps>
</arg>
<arg>
<name>varargs</name>
<fields />
<type>REPRESENTATION</type>
<reps>
<rep>
<class>java.lang.Object</class>
</rep>
</reps>
<default>varargs</default>
</arg>
</args>
<exs />
<reps />
</interface>
</meta>
For NetKernel and endpoints in a Standard Module, this metadata resource consists of intrinsic automatically generated metadata derived from the implementation (for example the verbs it handles). Other metadata is extrinsic and is declaratively specified as parameters at the point in the address space where the endpoint is instantiated - for example the name, desc, grammar resources.
The metadata structure of the standard module endpoint is internally held as HDS and as such is extensible with user specified fields. Currently it is only possible to programmatically extend the metadata model and it is not a documented feature since the META resource is used by many system tools. However we are currently undertaking the work to allow an extrinsic user-supplied open-ended metadata parameter to be declared. We expect this will be in the form of HDS which is able to be a list, tree or forest structure and so will allow arbitrary metadata formats to be combined at the point of declaration (eg, RDF, XML, Domain-Specific etc etc).
The endpoint identifiers of all endpoints in an ROC system act as a primary key and must be unique within any given address space. The active:moduleList endpoint in ext:system provides an aggregate metadata resource showing all public address spaces and the identifier of each endpoint in the space. With this breadcrumb "contextual association" it is possible to find and issue META requests to any endpoint anywhere in the system. Many of NetKernel's system tools use this resource oriented metadata as the basis for their operation.
It follows that this, and perhaps some simplified user-centric accessors, will enable very elegant aggregation patterns of application-specific user-specified metadata resources. We anticipate that this will provide significant opportunities and go a long way beyond the capabilities of low-level programming language metadata models, such as Java annotations, to allow general metadata driven application architectures (as recently demonstrated by Brian Sletten without even having the upcoming capabilities).
Currently META is defined in ROC and implemented in NetKernel, but it does not have an analogue in the World Wide Web - however, it would be relatively straight forward to add this verb to the HTTP methods.
As with the previous methods, the Parameterized META approach is localized. Which makes it convenient, but it also has a little friction with respect to Axiom #9 since its metadata is tightly coupled. Even so, it still satisfies Axiom #9 since more than one form of metadata resource can be simultaneously associated with the endpoint. Also unlike before, it satisfies Axiom #6 since this is a true resource representation and is requested in the ROC domain and so can be transrepted/cached etc.
A draw back of this method is that the metadata resource is for the endpoint and not one of the resources that it may be the accessor for. As mentioned, there is often a close correlation, but it means that the metadata supplied is for the entire set of resources it manages. Which is great for access control, non-functional architectural configuration, logging etc etc but falls short of the even more general approach offered by other patterns we'll see in a moment. That said, it still significantly exceeds the capabilities of Annotations.
Extrinsic Metadata Resource
The most general model for contextual association of metadata is to acknowledge that metadata is a first class resource in its own right with an identity (By Axiom #1). A true metadata resource must exist in an address space (By Axiom #2). The information in the metadata resource may be requested and reified to a concrete representation (Axiom #3). It may be static (pre-defined) or dynamically computed (Axiom #4). It may be transrepted (Axiom #6). It may be composed, aggregated and transformed to form other resources (Axiom #7).
So far, so like any other resource.
We do not care what the metadata expresses, but it must be contextually associated. But, since it lives in an address space it cannot, as we've seen in the previous models, be locally associated. Therefore it must contain a direct or indirect reference (identity, link) to the resource with which it is associated.
In certain communities you may hear the term "linked data". We won't adopt this term here since we're trying to be as general as we can and it has some pre-existing connotations especially, as we'll see, a built-in mono-spacial assumption.
Finally, since the metadata resource is entirely independent from the contextually associated resource it follows that this pattern fully satisfies Axiom #9. Any resource may simultaneously be associated with arbitrary numbers of metadata resources.
Mono-Spacial Systems: Semantic Web

The use of RDF structures located in the World Wide Web is an example of this model in a single address space (the Web). An RDF resource may be located in the Web address space with a URL. The resource(s) it is associated with are explicitly referenced in the RDF graph. Sometimes relative URIs may be used where the identity of the metadata resource provides the context to resolve these to an absolute identifier.
RDF is a graph of triples and it implicitly assumes that there is only a single address space in which all resources are located (the Web). Therefore it may reference other RDF metadata resources in the same space and so introduce secondary contextual associations for the resource. Forming a distributed web (superset) of metadata.
General multi-spacial ROC systems
The extrinsic metadata resource pattern is the most common metadata model used within the NetKernel ROC system.
It is seen employed in single address spaces - for example it is the way that general configuration metadata is automatically discovered for the relational database tools - whereby they request a "standard resource" identifier res:/etc/RDBMSConfig.xml.
However its power is most readily seen when we consider that a NetKernel ROC system consists of multiple independent address spaces. (Imagine that there were unlimited parallel World Wide Webs of arbitrary scale and you'll have a glimpse of general ROC.) Such a system must have metadata driven applications allowing aggregate metadata resources to be used to provide operation, configuration, description etc etc across and over the system.
The best way to describe this model in action is to consider the specifics of the "res:/etc/X" pattern. For example consider the NetKernel XUnit test system, the documentation application, the search system, the space explorer, the nCoDE runtime development environment etc etc.
The diagram below shows a metadata driven application which requires an aggregation of metadata resources resident in arbitrary independent spaces.
The essence of the pattern is that we may present suitable metadata to such applications by implementing a resource in the address space which has a common name in each space (at least those spaces wishing to share this metadata).
For the NetKernel tools we have adopted a convention that their metadata resources will use identifiers in the res:/etc/system/* resource set. Hence documentation is discovered at res:/etc/system/Docs.xml, unit tests at res:/etc/system/Tests.xml etc etc.
A tool requiring an aggregation of the metadata resources must interrogate all the spaces to discover if they provide a res:/etc/system/X resource. This is relatively simple to achieve since the kernel provides a resource which is the set of all (public) address spaces. All that is required is to use this list and to knock on the door of each space and request the metadata resource (shown in the diagram, where for clarity we've just called the metadata resource "X").
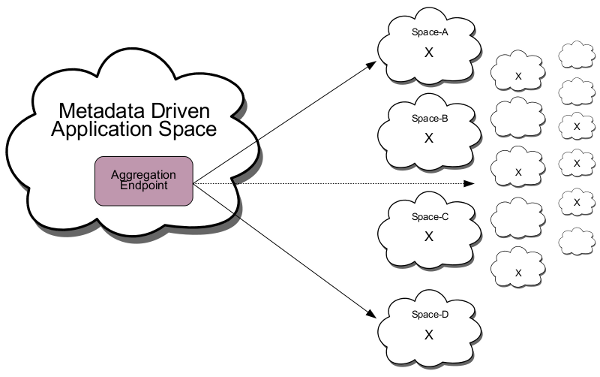
Each metadata resource X has within it a direct or implicit reference to the resource with which it is contextually associated. So for example each <doc> entry has a reference to the documentation resource which it describes, equally for unit tests etc etc. Importantly the identifier need not be globally unique - it is sufficient that it is contextually relevant from the point of reference of the metadata resource in the address space.
However, it is beholden on the aggregator that it should maintain a record of the spacial context for which the metadata resource was aggregated - so that, by breadcrumbs, the relevant related primary resource can be disambiguated should the metadata be of interest.
Once the aggregator has obtained the super-set of metadata resources it is free to use this as a resource within its application domain. For example, to show a table of contents of documentation, to request and render a composite view of a document, to show and provide execution of a unit tests etc etc.
As we've said, metadata is frequently used in order to find "resources of interest" - it follows that usually a metadata driven application will subsequently actually want to access the primary resource which is contextually associated via the metadata.
It would be quite possible, with the knowledge of the space and resource identifier, to construct a request for that specific primary resource in the application. However this use case is common and so there is a tool to do the work for you. We call this type of request the "wormhole pattern" and we provide the active:wormhole tool in layer1.
Aggregator Implementation
It is relatively straightforward to implement an aggregator endpoint to implement this pattern. However, since it is so common, we provide the active:SpaceAggregateHDS tool in layer1- which is specific to the HDS resource model and which requests a named resource from every space in the system to create an aggregate HDS metadata resource.
HDS
We use HDS as our standard internal resource model for metadata for the following reasons:
- The HDS structure is a flexible name-value node which may have one parent and multiple children.
- Its flexibility allows it to support list, tree and forest structures.
- It supports arbitrary comparator filters to apply efficient sub-setting operations.
- It may be inverted to provide a value-keyed map for "indexed operations".
In short, with a simple and very computationally efficient data structure it provides all the flexibility we have needed to operate the NetKernel system.
One of the singular benefits of HDS is that an aggregate resource may be rapidly sub-setted by using XPath expressions. Path expressions are easily comprehendable by human beings and they are essentially a continuation of the resource address space - since they are a resource identifier to the subset of a resource, resolved within that resource. XPath expressions on an HDS structure result in iterable node lists which are very simple to process and can be easily presented as resources to either synchronous or asynchronous sub-processes.
Of course, as I've said, axiomatically, the representation form of metadata resource is irrelevant. So if you have a specific need for another representational resource model then just look at the source code for the SpaceAggregateHDS tool and implement your own aggregator - its dead simple.
Power of the Extrinsic Metadata Resource model
To see the full power of the general extrinsic resource model we should consider the formal ROC foundations again.
Since these metadata resources are in the address space they may be transrepted (Axiom #6) - which gives innate decoupling between the metadata provider and the metadata driven applications.
However the most powerful point is to understand that any resource may be dynamically computed (Axiom #4). It follows that the NetKernel system tools are completely open to dynamically computed extensions (for example, the dynamically generated boilerplate for an endpoint's documentation, the dynamic reconfiguration of the nCoDE palettes etc etc).
Furthermore all metadata resources and composite aggregates (Axiom #7) are cacheable with associated dependency consistency, as with any other ROC application. Therefore metadata driven ROC applications exhibit the same scaling and computational efficiencies as exhibited by any other ROC solution.
Finally, there is a semi-magical consequence of this pattern. It provides the basis for the "dynamic import" pattern, in which the spacial architecture of an entire ROC solution is dynamically structured based upon aggregate metadata. NetKernel supports metadata driven architecture.
Its not all roses though, as ever there is an engineering balance to consider, having an extrinsic relationship with independent metadata resources is more flexible but the trade-off is convenience. Its generally less hassle at development time to bind metadata tightly at the point of origin (as shown in the locality factor of the other methods). However inconvenience is a one off cost, whereas metadata has value for a long time. You may recognise that the extensible meta parameter approach we are proposing is a half-way-house compromise that will be perfectly suitable for certain patterns and still be pretty convenient.
Engineering is an art form. Its all about finding an elegant balance.
Summary
Hopefully this discussion has demonstrated how the wider-perspective of Resource Oriented Computing allows us to uniformly treat metadata as just another resource. Everything is a resource.
There are still many things I could talk about. Like for example, I slipped in the term "aggregation" and then didn't explain it. Just off the top of my head we could go into aggregation with respect to...
- metadata as extracted sub-set of the resource
- metadata as side-effect state (logging)
- metadata as measurement of operations
- metadata as creative artefact
I've also stepped back from a full discussion of the semantic web. You can be sure I have opinions and ideas here - but I prefer to speak when I've got concrete solid examples to back-up what I'm talking about. So that'll have to wait for another time.
I'll close with this thought. Back at HP in days of yore, John Erickson used to bang the table (literally) and, eye's popping and veins extended, scream: "Metadata is the lifeblood of e-commerce". Well "Jahn", I'll steal your thunder...
Metadata is the lifeblood of ROC!
and, maybe, just maybe, I've convinced you that...
ROC is the foundation of metadata
* Of course any whitepaper can only be a pale second-order expression of ROC. The way to really understand it is to actually engage with an ROC address space - it is a dynamic and living thing. You can get to grips with ROC for real by getting NetKernel and playing with it while reading the extensive documentation that is included.
Corollary: The Search Giant's versus RDFa
Incidentally, the discussion above may help offer perspective on an interesting skirmish over the future of the Web. You may know that the leading web search engines (Yahoo, Bing and Google - though Yahoo uses Bing so there are only two parties really) have recently published and promoted a microdata specification for attribute metadata in HTML resources...
Even though they claim that they will still aggregate RDFa it is actually a pretty strong strategic play.
Why so? Well they say that their format is extensible and that "given adoption" they will recognise commonly adopted extensions, but that means that only metadata resources which are "blessed" are allowed into the walled garden.
You would hope this happens fairly quickly, a cursory glance at the recognised types in the full type list shows how laughably primitive the implementers of the format have been. I'll not even get into the innate cultural imperialism. Suffice to say that TattooParlor owners will be happy - but that TattooParlour owners are plumb out of luck.
Hopefully, what I've shown is that "contextual association" is the essence by which a resource is said to be metadata. But by having their own blessed format, it ensures that the search giants are able to build metadata driven applications that are specifically tuned for this. In essence it allows them to guarantee and maintain control of the "context" by which you see the Web's resources.
This is reinforced when you see that this is a centralised model and it guarantees and reinforces the role of the aggregator as mediator to information. Search algorithms are not open to inspection, and this specification offers no warranty that your page rank will be undamaged should you choose not to use their markup.
But then what do you expect, being the central aggregator and tuning the sub-setting of aggregate metadata resources is their business model.
Anyway, ultimately and fundamentally the format of metadata is a dull and uninteresting thing. Its your choice. But if it were my data and I wanted to describe it - I'd hope that using open extensible formats would be a better long term decision.
Euro-Bootcamp

The Bootcamp that preceded the NK West conference was well attended and proved to be an effective way for many people to get their feet wet with NetKernel and ROC. We also know that due to the travel logistics many people outside of the US couldn't make the conference. So we're wondering if there'd be interest in us doing a one or two day bootcamp over on the East-side of the Atlantic?
This is a tentative idea at the moment and we're trying to gauge interest. Off the top of my head it'd likely be in the October time frame and somewhere easily accessible in Europe.
Last week's beer-related idea resonated and we received a very kind offer of a venue in Brussels - which is the crossroads of Europe and with it's excellent Beer and its radical new idea of a graph-structured experiment in government would be a cool place to meet.
Drop me a note if this interests you and, all things being equal, we'll arrange things accordingly.
Have a great weekend, I'm going to lie down in a dark room for a bit.
Comments
Please feel free to comment on the NetKernel Forum
Follow on Twitter:
@pjr1060 for day-to-day NK/ROC updates
@netkernel for announcements
@tab1060 for the hard-core stuff
To subscribe for news and alerts
Join the NetKernel Portal to get news, announcements and extra features.
NetKernel will ROC your world
 |