|

NetKernel News Volume 3 Issue 11
January 13th 2012
What's new this week?
- Repository Updates
- Server Maintenance Status: Case Study
- Tom Latest
- ROC Memory Analysis
- Towards a Resource Oriented Model of Biology?
Catch up on last week's news here
Repository Updates
The following update is available in the NKSE and NKEE repositories...
- security-core 1.5.1
- Added active:pkiSignStandard, active:pkiVerifyStandard to provide standard RSASHA1 signing. (Thanks to Brian Sletten for highlighting this requirement)
The following update is available in the NKEE repository...
- nkee-apposite 1.30.1
- Add support for RSASHA1 signed repository with legacy signature supported.
The following update is available in the NKSE repository...
- apposite 1.27.1
- Add support for RSASHA1 signed repository with legacy signature supported.
Server Maintenance Status: Case Study
We successfully completed our hardware migrations over the weekend - total downtime was under 30 minutes. All services are operating normally.
For those who like to the know the details - all our systems run on NetKernel. We always use the latest release in production and we update our production servers with any proposed repository updates before we release them into the public repositories.
For the last four years we've been running Ubuntu Server 64-bit LTS on our primary physical server platforms. We use KVM virtualisation as the platform for our cloud servers with libvirt for management and administration.
Our virtual servers are also Ubuntu - with a mix of older 8.04 LTS and newer 10.04 LTS versions. Each server has a recent (but not bleeding edge) Java 6 release. Each server has a virtual bridged NIC with direct access to the public internet - this is the interface which the NetKernel instances are exposed through. Each server also has a bridged private network providing a backplane over which database traffic runs.
Typically our virtual cloud servers are given 500MB of RAM. Our NetKernel instances run on a JVM with 196MB heap (although we recently found that Chris Cormack's nk4um is best with 256MB heap).
The HTTP stacks on our NetKernel servers each have a custom Front-end-Fulcrum - this is necessary so that the HTTP server config for various virtual servers (domains) can be configured with appropriate SSL etc.
Our HTTP config uses NKEE's asynchronous HTTP handler - this means our servers manage all HTTP requests using non-blocking NIO (2-threads) dispatched to the ROC domain with asynchronous (threadless) requests.
So our entire HTTP stack runs on two threads and is non blocking. We also put the throttle overlay between the HTTP transport and the HTTPBridge - this provides an asynchronous non-blocking impedance match between the logical requests generated by the HTTP transport and the NK kernel's assignment of threads to those requests.
All of our servers run more than one application for more than one virtual domain. Some servers are running half a dozen different independent applications and services.
Web-applications typically see cache hit rates of between 20 and 40% - though some pseudo-static applications (like this wiki) are virtually 100%.
Tom Latest
Here's the latest from Tom. Please also don't forget that it would be really great if you can lend Tom some time to read/review the current draft of the Practical NetKernel Book.
Tom's Blog
This week I show an example of how to leverage your existing knowledge of scripting languages to develop NetKernel tools.
http://practical-netkernel.blogspot.com/2012/01/accessible-accessors.html
Feedback or ideas for future posts are welcome (email below).
Tom's Book
Since I am now working against a deadline for the O'Reilly release the book is quickly moving towards the 1.0 status. Chapter 8 on nCoDE is complete, several new ROC Talks have appeared.
As always I need your feedback, which is welcome at practical<dot>netkernel<at>gmail<dot>com.
ROC Memory Analysis
You may wonder how we can run our production servers with multiple applications in only 196MB of heap? Well firstly, part of the answer lies in our asynchronous HTTP stack, but more importantly in the ROC domain, a request is not a thread. Recall that unlike a regular Object Oriented application server, we are not assigning a thread per request and just letting it run freely to progress through the object callstack (lets call this the "free-running" model).
In the free-running model, at any given point in time, each thread will instantiate any necessary object state to do its work. Between the outer-edge of the server and the lower-edge talking to a persistence layer (database etc), there will be threads at all levels of the callstack. But we can say that statistically on average any free-running thread will be responsible for an average amount of state (heap memory) - lets call this average S.
But here's the catch - a free-running thread only makes progress (does work) when it is scheduled to the CPU by the underlying operating system. If you have more threads than CPUs, you will necessarily see your free-running threads progress through the tiers of your architecture in fits and starts. But even when they are not scheduled (and so not making progress through the call stack) they are still requiring an average state (memory) S per thread.
Lets assume we have a 4 core CPU and we have an average load of 100 concurrent requests (not untypical for a small/medium web server).
We see that a free-running model would require an operating heap (Hfr)
Hfr = 100S (1)
Now lets consider NetKernel. If we have 100 requests, we asynchronously handle these and issue them as logical ROC requests (not threads) to the ROC domain. With the throttle in place we hold the requests at the edge of the architecture waiting until the NK kernel schedules them. We make the throttle admittance be 4 - ie we allow 4 requests through concurrently, other requests are queued (but are not blocking threads).
To start with, lets assume that when a request is admitted into the ROC domain through the throttle then it has the same internal "stack" requirements as if it were in a free-running system and will, on average, require S amount of state per scheduled request (running thread).
But we also have to account for the fact that a queued request has associated with it a certain amount of state - lets call this s (small-s). Therefore we see that a NetKernel system would have...
Hroc= 96 s + 4 S
Now lets consider how big s might be. Recall that we have asynchronously received the HTTP socket event and then constructed an ROC request and asynchronously issued it into the ROC domain, to be managed at the edge by the throttle. The HTTP state has not been parsed or processed in any way (so has negligible foot-print), the ROC request is negligible since it is not state bearing (remember all of NK state is pull-state-transfer), the throttle and its queue is also negligibly small. So its safe to say that s << S.
In engineering maths, when we see this type of size difference between scalar variables, we can validly assume that to the overall model s is insignificant, which is to say, it is effectively zero. It follows that a good engineering approximation for Hroc is...
Hroc = 4 S (2)
So combining (1) and (2) we see
Hroc/Hfr = (4 S)/(100 S) = 1 / 25 (3)
So as a first approximation we see that, in this scenario, an ROC solution will require 1/25th the memory of a free running solution. But we're not done yet. Lets reconsider if our assumption that in NK the average state per sheduled request is S?
This is where it becomes less easy to be analytical since we're dealing with statistical distributions, but we know that our production servers are running at somewhere between and 20 and 40% cache hit rate. For our approximation lets say our hypothetical NK system is finding a 30% hit rate. What does this mean?
Well as a very first approximation we see that it means that the average state per request in the ROC domain cannot be S, it (lets call it S') must be a maximum of 0.7 S - since by definition,what caching really means is that more than one request is sharing overlapping common state.
But we also know that, since NK thermodynamically balances the cache, a cache-hit resource is disproportionately valuable. The cache holds only the most computationally costly state - or, in other words, it would require a disproportionate amount of transient thread generated computational state to compute each cache-hit resource.
Without analysing a real system we are waving our finger in the air. But my instinct and experience would estimate that S' is something approximately like...
S' = 0.25 S = S /4 (4)
We can therefore recast (2) as...
Hroc = 4 S' = 4 S / 4 = S (2a)
and so (3) becomes...
Hroc/Hfr = 1 / 100 (3a)
Which is a theoretical approximation of 100x less memory!
But let's not get too far ahead of ourselves. We've forgotten one thing. The cache is state, it constitues all the overlapping state that is normalized across the requests plus the other "garbage state" that is unreachable between requests; and of course it occupies memory. How much, is time and statistically load-dependent - but from experience we observe for our production servers that the operating memory for a full cache is typically about one-third of the 196MB heap.
In fact what we try to aim for in a balanced system is 1/3 of the heap used for cache, 1/3 of the heap used for transient GC-able object state and 1/3 of heap free as a margin of error engineering safety factor (this is demonstrated in snapshot of the heap/cache of this very server shown below)
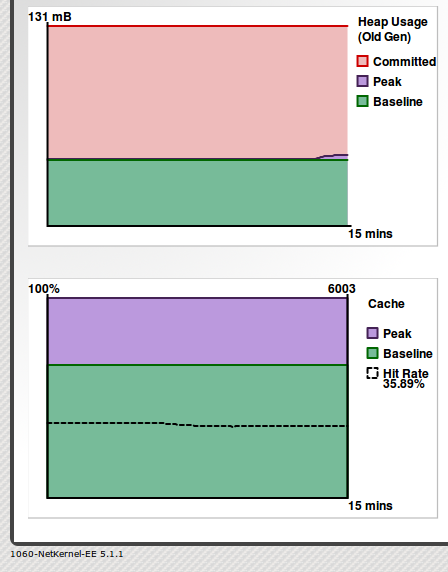
You really shouldn't take my word for it - you should get hold of NK and try some experiments for yourself. But I have not in any way exaggerated the numbers above based on our own production cloud servers. I can also state that the normalization of state is not at the expense of throughput - since the computational efficiency of discovered common state is a huge performance gain.
But in addition, you can see that we are creating approximately 96/100th less transient state (garbage) and therefore you are not burdening the JVM/OS with as much GC work - which is returned to the overall system as an additional gain in your server throughput.
And, if you think our servers are not typical, then consider this. NetKernel was recently fronting a very very large web-property during a seasonal peak load of more than 1 million request per hour - it was using eight instances, but the load could easily have been carried by just four.
Hype Fatigue
I'm sure you are sceptical. I know I get kind of tired by this industry's hyped claims and biased-analysis. But NetKernel is carrier-class infrastructure and its power derives from real hard-core engineering science.
But the thing that niggles me, is that while performance benefits are real and these are conveyed to the bottom-line (how much cheaper is an AWS cloud server with 512MB than one with 1, 2 or 4 GB? Answer: its non-linear and typically greater than 10x). But you know what? Performance operational benefits are only marginal when considering the overall enterprise solution costs.
The real benefits of NK/ROC are the speed, elegance and engineering malleability of building systems in the ROC domain. Labour costs outweigh operational costs - and ROC's real impact is in the speed to solution, its evolvability and readiness to embrace change. In real-terms these benefits are priceless, since with ROC you get to access an entirely new scale of solution.
Don't believe me? Look at the Web. Ever seen any other IT system in history grow and evolve like that? The web is just one very simple ROC architecture. There's so much more potential its breathtaking...
Towards a Resource Oriented Model of Biology?
Actually, there is an information system that is more impressive than the Web. Its called Biology. Let me very briefly explain where my head is at...
Once you begin to get familiar with the normalized computational state and the inherent malleability of ROC - its hard not to want to follow the implications and look around to try to spot its patterns in other systems that might share some or all of its elements.
It seems self-evident to me that biological systems are thermodynamically optimized information processes...
Granted this insight, about five years ago, I started an "interdisciplinary conversation" with a leading expert in the field of cancer. It quickly became clear that, what the medical/biological world calls "cancer", we in the computational world would call "an infinite recursion". That is, fundamentally, from a computer science perspective cancer is a manifestation of the Turing Halting Problem (or if you'll forgive my insatiable appetite to generalize, its the hard-edged reality of Godel's incompleteness theorem).
I've had a lot on my plate these last few years - so I tinkered around with some models of cancer implemented in the ROC domain - but that's as far as I got. But over the last six months my interest in biology has been stirring again.
I recently read Richard Dawkins' "The Greatest Show on Earth" - which, irrespective of his sometimes strident focus on convincing the religious (I have the theme tune to Mission Impossible in my head), provides an absolutely beautiful contemporary snapshot of the state and understanding of modern biology.
This re-awoke and re-enforced an observation from my earlier foray into thinking about an ROC model for cancer. Viz: biology as a science currently has a big problem. It has unfathomed the genome, but, much to its chagrin, according to its classically oriented point of view, there doesn't seem to be enough information. That is, the information expressed in DNA, and created uniquely for each individual in the first moments of conception, doesn't seem to be sufficient to describe the emergent complexity of the adult organism.
Now when I first considered this, it was stated to me just after the time we had worked out the general contextual ROC model (first appearing in NK4). We had only just started exploring the patterns of general ROC but even then it had appeared to me that biologists were taking a classically "code-like" analysis - as you might do if you had the execution state of a program and its source code and were trying to infer from these the underlying physical computer.
But ROC was beginning to show us a world in which we deliberately relegated code (and languages) to the second-order and gave primacy to abstract resources - that is, information. It felt like the focus on DNA-as-code was to miss the contextual information system.
You call it Enzyme I call it Endpoint
There's a chapter in Dawkins in which he discusses the beautiful and complex role of enzymes as catalysts in the metabolic processes of cells. He describes how cells contain a "soup" of chemicals (technically called the substrate) and the arrival of a certain protein at a nucleation point on an enzyme will catalyse (by extraordinary rate-factors of millions of times) the building from the soup of new proteins (and I guess other "stuff" - but the chemistry is not really relevant here).
This was where I got excited. You see I started reading the book because I had a strong sense that evolutionary nature is a good engineer. A good engineer seeks to optimize solutions. If ROC seemed like such a good way to engineer efficient and flexible information systems. And biology is an information system. Wouldn't bits of biology have also discovered and be using bits of ROC?
I got excited about enzymes because they suddenly seemed very very familiar.
The arriving protein message (yes biologists call this discipline cell signalling and the proteins conveying information "messages") floats around in the soup until it meets an enzyme. The enzyme has an elaborate chemical structure which provides a perfectly shaped binding point to which the message-protein can attach - this combination activates the enzyme and drives the catalysis of a reaction in the soup resulting in the rapid generation of new chemical products.
But, step away from the physical domain... Look at this from the ROC abstraction's perspective...
- There is a space containing the set of all possible abstract resources (the soup).
- There is a message (it is a 3-dimensional protein but it can easily be shown that it is mathematically expressible as an opaque token which in ROC we call a resource identifier).
- The identifier floats around in the space (in ROC we say it is resolved by the space - no doubt it meets lots of enzymes that don't match).
- Eventually it meets the enzyme.
- The enzyme expresses a geometric structure which matches the identifier (an enzyme's "activation site" is exactly equivalent to an ROC endpoint's grammar).
- The presence of the request (message) at the enzyme causes the catalysis of the soup to drive a reaction to produce a new product (in ROC we say this is the reification of the physical representation state from the abstract resource set - or sometimes we say the endpoint computes the representation for the request).
If we're really on to something we ought to be able bring in to play other ROC axioms and use these to make predictions.
In ROC a resource may have one or more identifiers. That would suggest that a given enzyme could be activated by more than one protein. So we might predict that enzymes may resolve more than one protein - the variation in the protein may likely catalyse variants of the representation soup state (an endpoint is an accessor to state, an enzyme is an accessor to products).
But we can also expect that there will be entirely different proteins that may express an exact match with the enzyme's activation site (grammar) ... and then you think a bit more... and you vaguely remember what a virus does - on its surface it expresses protein(s) that replicate some subset of other message proteins in order to pretend to be something its not (a virus is firstly an opaque token that is a superset of a genuine message).
Consider also, that it would be possible to have many different implementation models for spaces (cells) - just as its possible to have more than one implementation of a space in ROC. But it would seem practically more efficient to have one general model that can be constrained to suit any given task. It follows that the soup, the nucleus, the other bits and pieces of cells all share a common model. We see this in the basic observation that the soup of potential state is common and it exceeds the requirements of any given cell (just like the standard module's Space).
So just like in ROC, where we create architecture by constraining the infinite potential of an empty address space, so any given type of cell constitutes a set of constraints such that its potential to perform information processing is suited to the application at hand. Think of nerve cells in the brain, liver cells, the photo-receptor cells of your retina. Think of fulcrums, of resource-model libraries, of applications, of services, of transport libraries.
DNA? DSL!
And then you come to DNA. Why doesn't it have enough information? And even so - how can the same DNA molecule exist in the nucleus of every cell of your body and yet clearly have differing roles in each type of cell?
Here's my conjecture. And its based on a well known ROC pattern. Could it be that the DNA in the nucleus of a cell is an instance of the runtime pattern? That is, it is an endpoint which is "coded" to reify state based upon the transfer of state (by interaction with proteins). It is not a blueprint for the execution of the cell (or indeed the higher-order organism) but rather it is a universal machine that will compute new state based upon the receipt of transferred state. It is therefore not a first order description of the system - but a second order gateway to the first order state.
Clearly it is constrained by its context as to what state it is able to reify - and clearly it is not Turing complete - its something like a DSL-runtime. But within one cell it can readily compute many many different representations.
One essential requirement for life is that DNA must be self-replicating - which it does when it receives a request with the identity of DNA-polymerase - or probably its the other way round - the DNA is the message received by the polymerase that reifies a new instance of the DNA state (but if you've been following these articles, you'll accept that this is just as you'd expect with ROC's innate identity/state duality).
For an ROC metaphore consider the XRL or TRL runtimes - they are not "programming languages" but when resolved in the context of an application's address space they are able to reify the contextual state for a given request. But the same runtime yields different representational state in different application spaces - they are contextual. It's not difficult to imagine XRL state that would, like DNA-polymerase, replicate the state required to implement the XRL runtime!
DNA looks awfully like a specific instance of a familiar pattern?
Cell Signalling, ROC Architecture Showcase
At this point, I began to get carried away. I bought a copy of "Cell Signalling" by John T. Hancock an advanced undergraduate/early post-graduate text book.
What you quickly learn (and as a Physicist you pale from) is that Cell Signalling is a very complex world of vast numbers of chemical reactions. It has taken the best part of 50-years of painstaking experimentation to tease apart just a small number of the protein messaging cascades that occur in the real biological world.
But undeterred (and lacking the 2-3 years of undergraduate bio-chemistry) I read on, attempting to filter the noise present in the detail and to focus on the architectural patterns.
For example, it is clear that most cell signalling is physically constituted as information amplification chains - created by cascading avalanches through many intermediary message forms to drive a certain result. The chains are not monotonic but often branch into parallel sub-cascades that create new state that drives further cascades. But this is exactly the same as every ROC application making a cascade of sub-requests which may start new asynchronous request sequences.
So you ask yourself: Wouldn't a cell (address space) require an endpoint that initiates the first request? In ROC we call this pattern a transport - its the "event detector" that constructs and issues the initial ROC domain request, surely an ROC model of biology ought to have something equivalent...
Step forward receptors - an external event detector (events include: receiving protein messages, hormone threshold triggers, electrical impulses, light, scent molecules etc, etc). When triggered by an event a receptor initiates the release of a protein message into the internal cell. Wow, this couldn't be a better analogue to the ROC domain - yes indeed, the cell does express on its membrane something(s) we would immediately classify as a transport in ROC!
So what about communication between address spaces? What about the import pattern (an endpoint that mediates a request to another space)?
Step forward inter-cellular channels called gap junctions. These endpoints have an interface that is just large enough to accept messages but too small to let the soup (representation state) leak - exactly like the import endpoint.
But what about state management? What about caching representation state?
My understanding is incomplete - and its not clear that there could be a one-to-one correspondence between the ROC cache (normalized state) and a biological cell - but you would expect that "the soup" inside the cell will hold on to the generated representation (products) for some time before normalizing back to a steady abstract state (By what means? Who knows? - but as an information system it is essential that it is reproducible and repeatable under the same signal so it must be the case that it renormalizes its state over some time period - yes just like ROC we would expect a biological system to be locally stateless).
So presumably if the same initiating request were to happen before all (or some) of the representation (product) state had renormalized (been GC'd) then some (or all) of the pathways of the information cascade would not have to fire. Which is exactly (precisely) what we do in an ROC system to minimize energy (and entropy, and, as shown above, computational state).
I don't know. I have a clear picture of ROC and little knowledge of the details of the biological systems - but each time I've thought about an ROC pattern and looked for a parallel in the biology domain it seems to be there. It all seems to make perfect sense in my head - but its a model and all models need to be rigorously tested.
Here's a testable prediction of the ROC model of biology. We know that abstract information may be refied to one or more physical representations. We also know that it is computationally efficient that physical representations can be transrepted by a suitable endpoint. (Thermodynamically, transreption constitutes an entropy transform). Surely there are enzymes (or other endpoint mechanisms) within the cell which implement the transreption role?
Discussion
Maybe I need to get out more and explain ROC to some academics (talking of which I'm heading to the States again this weekend). But it seems to me that when I say that ROC's potential to create large scale systems is unparalleled - I look at these biological analogies and I dream. What if we could make our information systems just half as robust, elegant and adaptive as biology. And then I think - well, you know, we really can. We have the same foundations, all we have to do is try...
I wanted to share this insight for two reasons. First I think its potentially really quite important and the more people who know about it the safer the knowledge will be. The second is, as ROCers who care about building practical things, you can take a look along the biology text book shelves and see a huge number of books describing real proven ROC architectures! We don't have to invent all the wheels ourselves.
As I said before, sometimes the potential is breathtaking...
Cheese Jokes

Recently one of the UK's formerly famous TV-chefs got caught shoplifting. For some bizarre reason he stole some cheese. This has led to a flurry of cheese related jokes going round. So, for no obvious reason, here's the 5 greatest cheese jokes of all time (with an extra sixth at the end for you ROCers)...
- What did the piece of cheese say when it saw itself in the mirror? Haloumi !!!
- What did the magician say when he pulled a piece of cheese out of his hat? Cheddar !!
- What cheese isn't your cheese? Nacho Cheese !!!
- What cheese do you use to hide a horse? Mascapone !!
- What cheese would you use to get a bear out of a cave? Camembert !!!
- What cheese do NetKernel users (and Biologists) prefer? Roquefort !!
ROCing the Twin Cities
I'm going to be in the Twin Cities area again next week from the 14th January - there's a rumour I'll be giving a talk at the local Java User Group (details to follow). But if you'd like to get together ping me on twitter (@pjr1060).
Have a great weekend...
Comments
Please feel free to comment on the NetKernel Forum
Follow on Twitter:
@pjr1060 for day-to-day NK/ROC updates
@netkernel for announcements
@tab1060 for the hard-core stuff
To subscribe for news and alerts
Join the NetKernel Portal to get news, announcements and extra features.
NetKernel will ROC your world
 |