|

NetKernel News Volume 3 Issue 40
October 5th 2012
What's new this week?
- Repository Updates
- Software Process Guide
- Tom's Blog - Neo4J on NetKernel
- Resource Oriented Analysis and Design - Part 7
- Resource Model Constraints
- Boundary Conditions: Constraining the Edge
- Elegance through Transreption
- Context is King
Catch up on last week's news here
Repository Updates
The following update is available in the NKEE and NKSE repositories...
- layer0 1.93.1
- Declarative request now trims leading and trailing whitespace which might be introduced by text editor formatting - thanks to Nick Spilman for spotting this.
- Simple grammar regex matching now supports full \w style patterns.
The following update is available in the NKEE repository...
- nkee-dev-tools 0.26.1
- Update to the login overlay to store login credentials in a common pds location.
Software Process Guide
It's been noted by enterprise users of NetKernel that it would be valuable if there were some guidance around software engineering process oriented towards Resource Oriented Computing and NetKernel.
Historically, this has not been a deliberate omission, but rather an area we have felt which is heavily influenced by personal choice.
Of course, we've touched on topics like IDE setup, testing, CCC methodology etc but we realize that we can go further.
ROC is significantly different than existing tools and approaches designed for object oriented development may need adaptation. Fortunately, however, many existing tools can still be used to good effect with a little know-how.
Therefore in order to capture a broad sample of useful material, we have started an initiative to collect hard won knowledge both from 1060 Research and The Community. Our hope is that it will build to become a comprehensive resource of available options and best practice.
Everyone is welcome to join in, in fact you're actively encouraged to use this resource, to point out what's lacking, contribute by adding, correcting and refining.
The Software Process Guide is a NetKernel documentation system book encapsulated in a module. We've taken the approach of placing this module on a public GitHub repository:
The repository is available here: https://github.com/tonbut/doc.sp. where you'll find a readme on how setup the module.
Tom's Blog - Neo4J on NetKernel
This week Tom describes his background as DBA and how this relates to Neo4J. He provides an integration module to work with Neo4J on NetKernel...
http://practical-netkernel.blogspot.be/2012/10/the-matrix-revisited-neo4j.html
Resource Oriented Analysis and Design - Part 7
Seventh in a series of articles taking a well understood domain problem and casting it as an ROC solution.
Recap
Last time we used linked data resources to determine the winning set resource. The game was essentially completed (at least as far as is necessary for the purposes of these articles).
Over the series so far, we have been employing an iterative development cycle moving between Composition and Construction (the first two C's).
Now we have a working solution, we can step back from the implementation details to look at the engineering integrity. Our aim today is to introduce extrinsic constraints so that in operation, the system always sits within a well defined and understood operational boundary.
We shall see that constraint should be applied with a light touch. A system with no constraint has unacceptable edges which can lead to compromised data-integrity (resource state) or operational inconsistency. However, an over-constrained system is brittle and becomes increasingly difficult to adapt and evolve.
Our ideal is a tolerant system that lies in a bounded "comfort zone" (in which data integrity is assured) but which is not internally prevented from adapting to future requirements...
Resource Model Constraints
The application of constraints necessitates us to look at the context in which our solution will operate. We can than assess the risk and introduce any necessary measures to bound the risk.
We will see that this assessment and the evaluation of the context allows us, as with the delegation of state to the edges, to seek to put our constraints on the edges of our solution as boundary conditions to the context.
So lets return our thoughts to part 2, in which we defined and implemented our atomic and composite resources.
You'll remember that we came up with the c:x:y resource for a cell's state. We also reified sets of cells with the cells{...} resource. We showed how certain named sets of cells could provide semantic labels that would be useful to our problem - so we introduced the composite resources row:y, column:x and diagonal:z.
Our implementation of c:x:y was achieved through a mapping to the pds: (and fpds:) address space.
Our first inclination might be to put an upper bound on the size of these resource sets. This is very easy to do, we can simply limit the extent of the "platonic" reifiable resources that our address space contains (you remember how I said in part 2 we can think of the space as containing all resources?).
Modifying the grammars on our atom and composite mapper declarations can easily constrain the space. For example the unbounded endpoint...
<simple>c:{x}:{y}</simple>
</grammar>
...can be "tightened up" using the simple grammar's support for an optional regex on the argument. Here is a new grammar that will only resolve c:0:0 through to c:2:2 inclusive...
<simple>c:{x:[0-2]}:{y:[0-2]}</simple>
</grammar>
Here's a tightened up row...
<simple>row:{y:[0-2]}</simple>
</grammar>
And a set of cells{} that is bounded...
<simple>cells\{{operand:(c:[0-2]:[0-2],?)+}\}</simple>
</grammar>
Clearly with these constraints our resource model is now strictly bounded. Literally, there are no other possible resources in the address space and so our model is watertight. Nothing at all can happen here that that we do not explicitly expect.
However, I would say this would be a mistake. We have assumed that the context of our TicTacToe application is universal. We have assumed that this resource model will only ever be used in that context. Why? We have constrained our model, but I think much worse, we have constrained our future opportunity.
For example, what if our TicTacToe game is so wildly popular (yeah really) and we decide we need a sequel. With our hard won market reputation for exciting cell-based entertainment, we could blow peoples minds with a Connect-Four follow-up.
You know the game, an array of 7 columns each 6 rows high. Player takes a turn to drop a Red or Yellow token into a column. It has precisely the same resource model as TicTacToe... We can get it to market in half-an-hour...
Oh wait...
Our resource model has been "welded to the TicTacToe context" - we can't do a 7x6 array with it...
I'm being deliberately ridiculous, but I'm making a serious point. An over-constrained set of resources does not provide any additional reduction in risk - but it sure does limit future opportunity. Bear with me a moment and I'll show how we can get exactly the same constraints and bounding risk for our TicTacToe and yet leave open the Connect-Four option...
For the sake of moving forward, lets reassess the cell constraint. If we simply say c:x:y must resolve any integer value of x and y then we allow for any array of cells.
So for example, our grammar would be...
<simple>c:{x:[0-9]+}:{y:[0-9]+}</simple>
</grammar>
And equally we can have any number of rows, columns etc...
<simple>row:{y:[0-9]+}</simple>
</grammar>
Lets assume for now that we're not going to make Chess games or Battleships, where we might want to have rows and columns distinguished by using a mixture alphabetical and integers for the x and y identity.
In the implementation you can download below, you'll see I've left the resource model with these looser, but still constrained, integer grammars. But, I have to tell you I am anxious that even with this loosening, I may have over done it and closed off the Battleships market.
Representation Contraint
Returning to our first perspective on applying constraints - as well as tightening the resolvable set of resources, we might also start to worry about the representation state. What if you SINK something that is not an X or an O?
Just as with the grammar, at this point in our architecture, why is it of any concern to us? We can already see that Connect-Four needs the concept of a colour for the resource state.
Now what if we do decide we want to crack the Battleships market and we decide the killer feature is to offer a user editable "Battleship Designer" ™. With our Battleships you can create your own navy...
No, we wouldn't store bitmaps in the cells (though nothing is stopping us), we would store identifiers to the resource that is the user defined battleship. We'd use linked data even within our resource model. Why not?
So, to our general cell resource model, why on earth should we care what the representational state should be in a cell?
Boundary Conditions: Constraining the Edge
Lets move our attention up to the application itself. In the TicTacToe game, we really do care that a cell lies on the board. So we need a constraint to ensure that a move cannot be made "off-board".
We can think of the locations of all valid cells as a set. What we need is to decide is a cell c:x:y a member of the valid set (ie is it on the board). Here's a quick and dirty way to implement this...
<grammar>
<active>
<identifier>active:validTTTCell</identifier>
<argument name="cell" />
</active>
</grammar>
<request>
<identifier>active:groovy</identifier>
<argument name="operator">
<literal type="string"> import org.netkernel.layer0.representation.impl.* cell=context.source("arg:cell") s=cell.split(":") x=Integer.parseInt(s[1]) y=Integer.parseInt(s[2]) if(!(x>=0 && x<3 && y>=0 && y<3)) { throw new Exception("Invalid cell: "+cell) } context.createResponseFrom(cell) </literal>
</argument>
<argument name="cell">arg:cell</argument>
</request>
</endpoint>
We can see that it parses the cell argument and determines if x and y lie between 0 and 2. If they do then it simply returns the cell identifier as its response. If it doesn't, it throws the teddy bear out of the pram.
So now the move endpoint can change this line...
cell=context.source("httpRequest:/param/cell")
To this...
req=context.createRequest("active:validTTTCell")
req.addArgument("cell", "httpRequest:/param/cell")
cell=context.issueRequest(req);
It will always receive a valid cell or, if an exception is thrown due to it being invalid, the move request is terminated and an ugly exception report is sent to the bad person trying to spam the game.
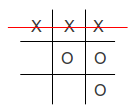
Here's what happens if a malicious hacker tries to play cell c:4:3...
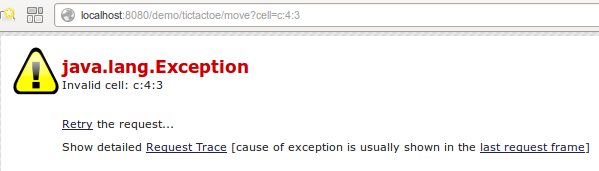
Our TicTacToe game has a boundary condition which satisfies our initial risk evaluation. It is now guaranteed that the resource model will only contain valid cells.
Aliased Decoupling
Before we go on. Lets reconsider the implementation of the move endpoint. Notice how we changed a request for the HTTP cell parameter httpRequest:/param/cell to one which asks the validation service if that resource is a member of the valid set.
But why are we hard-coding the parameter resource into the move? What if in the future the game is enhanced and we decide that the AJAX interface needs to use JSON as its resource model?
Actually, who says that the move endpoint is even going to be called by HTTP? What if we wanted to make a move by email, or using an instant message, or what about JMS (yeah really).
Why not be a little more resource oriented. A resource can have any name. Why don't we think of our address space as the abstract set and configure it so that it always has a valid resource for the current move?
Since in the last section we already provided the valid set of TicTacToe cells, we can easily provide the current move's cell identifier as a member of that set with a mapping...
<grammar>
<active>
<identifier>active:safeCellParam</identifier>
</active>
</grammar>
<request>
<identifier>active:validTTTCell</identifier>
<argument name="cell">httpRequest:/param/cell</argument>
</request>
</endpoint>
So now we can rewrite the move endpoint. It becomes simpler and has no need for knowledge of the location of the HTTP parameter address space...
cell=context.source("active:safeCellParam")
Representation State Constraint
Following the same reasoning, I added a constraint on the representation state. I consider there is a set of possible valid states (in this case it has two members "X" or "O"). I then provide an endpoint that allows any resource to be tested to see if its in the set.
For good measure, I introduce the same decoupling from the HTTP parameters with an alias of active:safeStateParam...
<endpoint>
<grammar>
<active>
<identifier>active:safeStateParam</identifier>
</active>
</grammar>
<request>
<identifier>active:validTTTState</identifier>
<argument name="state">httpRequest:/param/state</argument>
</request>
</endpoint>
<endpoint>
<grammar>
<active>
<identifier>active:validTTTState</identifier>
<argument name="state" />
</active>
</grammar>
<request>
<identifier>active:groovy</identifier>
<argument name="operator">
<literal type="string"> state=context.source("arg:state", String.class) if(!(state.equals("X") || state.equals("O")) ) { throw new Exception("Invalid Cell State: "+state) } context.createResponseFrom(state) </literal>
</argument>
<argument name="state">arg:state</argument>
</request>
</endpoint>
</config>
So now the move endpoint looks like this...
cell=context.source("active:safeCellParam")
state=context.source(cell)
result=null
if(state.equals(""))
{ state=context.source("active:safeStateParam")
context.sink(cell,state)
req=context.createRequest("active:checkSet")
req.addArgument("cell", cell)
rep=context.issueRequest(req)
ids=rep.getValues("/test/id")
result="OK"
for(id in ids)
{ req=context.createRequest("active:testCellEquality")
req.addArgument("id", id)
if(context.issueRequest(req))
{ result="GAMEOVER"
break;
}
}
}
else
{ result="TAKEN"
}
resp=context.createResponseFrom(result)And here's what a hacker sees if they try a dastardly "Battleships" move on the TicTacToe game...
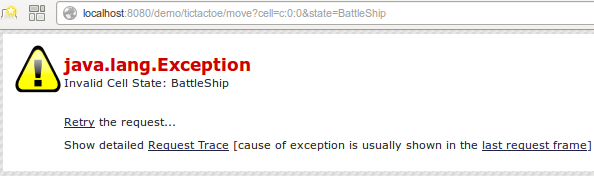
Our constraints are in place. The boundary of our system is defended. Nothing that we don't want to happen can happen.
Elegance through Transreption
There's one thing that sticks out though. Did you notice that I've hard coded parsing of the cell c:x:y identifier into the active:validTTTCell endpoint...
cell=context.source("arg:cell")
s=cell.split(":")
x=Integer.parseInt(s[1])
y=Integer.parseInt(s[2])
If you look back to last week, I have exactly the same requirement in the implementation of the CheckSet endpoint. Clearly parsing and obtaining the x and y values from a cell identifier is a requirement of our model which we overlooked in part one.
So far we have always treated the cell identifier as a string and so we have been required to slice and dice it. What I really need is a lower-entropy form of the cell representation. I need an optimal representation that gives me rapid access to x and y.
In fact I need a representation that has an interface like this...
package org.netkernel.demo.tictactoe.www.rep; public interface ICellRep { public int getX(); public int getY(); public String getCellIdentifier() }
and an immutable "value object" to implement this...
package org.netkernel.demo.tictactoe.www.rep; public class CellRep implements ICellRep { private int mX, mY; public CellRep(String aCellIdentifier) { String[] s=aCellIdentifier.split(":"); mX=Integer.parseInt(s[1]); mY=Integer.parseInt(s[2]); } @Override public String getCellIdentifier() { return "c:"+mX+":"+mY; } @Override public int getX() { return mX; } @Override public int getY() { return mY; } }
And a transreptor that, should I ask for an IRepCell, would be automatically discovered and would always give me the low-entropy representation...
package org.netkernel.demo.tictactoe.www.endpoint; import org.netkernel.demo.tictactoe.www.rep.CellRep; import org.netkernel.demo.tictactoe.www.rep.ICellRep; import org.netkernel.layer0.nkf.INKFRequestContext; import org.netkernel.module.standard.endpoint.StandardTransreptorImpl; public class CellParserTransreptor extends StandardTransreptorImpl { public CellParserTransreptor() { this.declareToRepresentation(ICellRep.class); } @Override public void onTransrept(INKFRequestContext context) throws Exception { String cellIdentifier=context.sourcePrimary(String.class); context.createResponseFrom(new CellRep(cellIdentifier)); } }
If I had such a thing I'd register it in my address space...
<class>org.netkernel.demo.tictactoe.www.endpoint.CellParserTransreptor</class>
</transreptor>
...and then I'd simply change active:validTTTCell to...
import org.netkernel.layer0.representation.impl.* import org.netkernel.demo.tictactoe.www.rep.* cell=context.source("arg:cell", ICellRep.class) x=cell.getX() y=cell.getY() if(!(x>=0 && x<3 && y>=0 && y<3)) { throw new Exception("Invalid cell: "+cell) } context.createResponseFrom(cell.getCellIdentifier())
...oh what do you know, it was easier to do it than it was to describe.
Now that I've got this I might as well refactor CheckSet to take advantage of it too. All thats required is to source the cell as an ICellRep. But I also notice that I am assuming that the checkset is pass-by-reference. I need to change the move to pass it by value so that it can be transrepted (parsed). That's just a case of addArgument() changing to addArgumentByValue()...
req=context.createRequest("active:checkSet")
req.addArgumentByValue("cell", cell)
I reckon that about wraps this up. But there's just one more thing...
Context is King
Did it ever occur to you that this is a pretty crappy and unscalable solution? Did you ever think: "Yeah right - but if he's going to make his fortune he has to be able to support the playing of more than one game at a time"?
No? Well I did. Remember back in part three I said...
PDS uses the configuration resource to determine a collection name for this set of pds resources (something that is called the "zone"). You can see that in my space I provided a very simple static <literal> implementation of res:/etc/pdsConfig.xml and declared my pds zone to be gobal:TicTacToe (remember this, we'll come back to it one day).
Look at the urn:org:netkernel:demo:tictactoe rootspace...
<!--Literal PDS Config-->
<literal type="xml" uri="res:/etc/pdsConfig.xml">
<config>
<zone>global:TicTacToe</zone>
</config>
</literal>
Now, what would happen if I moved the implementation of res:/etc/pdsConfig.xml from down in the low-level resource model. Up into the web application rootspace?
The answer is, absolutely nothing. PDS finds is configuration using the context of where it is requested (just as any resource is resolved in ROC).
The implementation I've used so far is an inline <literal>. So what would happen if I mapped res:/etc/pdsConfig.xml to a dynamically generated resource? What would happen if I dynamically generated the PDS config resource to be a unique zone for every unique visitor to the web page (or email listserv, or JMS message queue or ...)?
Can you see that with no change to anything other than the context of the application architecture, my application would now support unlimited, completely isolated, concurrent games? And every single isolated game would be normalized and have its state cached...

Download
You can download the complete solution here...
- urn.org.netkernel.demo.tictactoe-1.1.1-final.jar
- urn.org.netkernel.demo.tictactoe.www-1.1.1-final.jar
- urn.test.org.netkernel.demo.tictactoe-1.1.1-final.jar
Have a great weekend. I'm off to celebrate finishing TicTacToe by dancing Gangnam Style
Comments
Please feel free to comment on the NetKernel Forum
Follow on Twitter:
@pjr1060 for day-to-day NK/ROC updates
@netkernel for announcements
@tab1060 for the hard-core stuff
To subscribe for news and alerts
Join the NetKernel Portal to get news, announcements and extra features.
NetKernel will ROC your world
 |