|

NetKernel News Volume 5 Issue 13
October 3rd 2014
- Repository Updates
- Tom's Blog: Back to the Beginning Series Resumes
- How Push became Pull: What Pass-by-Value means in ROC
Repository Updates
There are no Apposite updates this week.
Tom's Blog: Back to the Beginning Series Resumes
Tom Geudens has resumed his series of Blog articles with two new articles in the series...
I provided a list to the earlier articles in a previous newsletter
Great stuff Tom! Good to have you back at the coal face!
How Push became Pull: What Pass-by-Value means in ROC
In the last two weeks, I've discussed the details of Pass-by-Value with two independent teams and a leading professor of computer science.
The first group, who I spent time with in Boston, are migrating a large scale NK3-based system to NK5, the other, on the West Coast, is developing a highly scaled content delivery network, the professor, well I suspect there will be a lot more to say about that at a later date...
I reviewed our documentation, and while it provides the details, it is concise reference material, so it would seem like a good idea to tell the story here in full.
Pass-by-Value
The thing about Pass-by-Value in ROC is there is no Pass-by-Value!
...hang on, let's back up a second, maybe we better agree what we mean by Pass-by-Value first.
But to do that, we have to stop thinking in terms of programming languages. Lets quickly remind ourselves of what pass-by-value and pass-by-reference mean.
Languages
Scott Stanchfield has written an excellent article explaining how Java is strictly a Pass-by-Value language. His definition of the two concepts is as follows:
- Pass-by-value
- The actual parameter (or argument expression) is fully evaluated and the resulting value is copied into a location being used to hold the formal parameter's value during method/function execution. That location is typically a chunk of memory on the runtime stack for the application (which is how Java handles it), but other languages could choose parameter storage differently.
- Pass-by-reference
- The formal parameter merely acts as an alias for the actual parameter. Anytime the method/function uses the formal parameter (for reading or writing), it is actually using the actual parameter.
If Java (or Java-based languages like Groovy) are your thing then read the full article.
But if you learned C (or even Assembler) you'll have a good feel for the dichotomy introduced by pass-by-value (values) versus pass-by-reference (pointers) parameters to functions/methods.
REST
So you know about pass-by-value in your chosen language. You also probably have an intuitive feel that REST is pass-by-value too.
REST supports "entity bearing" methods. The clue is in the name: for entity-bearing, read pass-by-value.
If you're a righteous follower of the RESTian-pact you might have used PUT, but even if you're a laissez faire free-wheelin' Web-hacker you'll have used POST.
With both POST and PUT, we provide a request body which is the value to be passed to the endpoint.
What do we mean by Value?
It seems like we know about two worlds. Programming languages and their function parameters, and REST endpoints and their entity bearing methods. Both allow us to pass-by-value.
Are they really different?
No they are not, but to see they are the same, we have to ask the question: What do we mean by value?
From a pure computer science perspective, what we mean by value is computational state - or more formally a set.
A value is the state (set) that the requested method/endpoint is to compute with.
Push State Transfer
Now that we understand that we're talking about state, we can also immediately see that Pass-by-Value is a form of State Transfer (as in ST in REST)...
With Pass-by-Value the state is pushed to the function/endpoint in advance of the endpoint executing its computation.
In REST this is self-evident - the body is pushed to the endpoint.
Computer scientists may split hairs on this, but pass-by-value in a language is the same.
In a language a pass-by-value method call creates a uniquely located state for the value that is to be computed with. This constitutes the pre-emptive combination (PUSHing together) of the Turing encoding of the computational function and the initial inscription of the state.
In both cases computational state is pre-emptively transferred prior to computation.
Pass-by-Value is Push State Transfer.
What's wrong with Push?
When you have a localized perspective of computation there is nothing wrong with Push. In fact it could be argued (and as is shown in Java), Push is safer and prevents the possibility of unintended side-effects.
However if you broaden your perspective - and consider that computational state is not the domain of a single function but in fact is the non-deterministic outcome of a complete system (such as the Web or ROC) - then we find that Push is a poor choice.
From a system point of view, Push requires that an information resource be reified (its value computed if it does not already have a representation) and pre-emptively transferred to the requested endpoint. The assumption being that the endpoint must require the state in order to respond.
In fact this is a poor assumption. Frequently we find endpoints (and software functions) that due to the condition of another resource's state never actually touch the state that has been passed to them.
Push therefore imposes a local cost threshold that from a system perspective could be avoided and so increases (maximizes) the system's total computational cost.
The cost overhead of Push is further compounded when we think about concurrency. With Push, everyone has to reify the state no-matter if the state is common or not. In other words everyone has to do the same work even if that work could be done once and shared.
Lastly with a total system perspective, pre-emptive state transfer travels "out-of-band" in the body of the request (or with languages, on the stack rather than as a memory location) - it follows that this state is not identifiable and, since we must assume that the state has been used to compute a result, since we do not know uniquely what that state was, we cannot cache the result. This is a long-winded way of saying a truism you will hear in REST...
You cannot cache a POST
The Breakthrough Moment: "Everything is a Resource"

In the first versions of ROC (up to and including NetKernel 3) our thinking had followed the conventional model discussed above. If you had a computed value and you wished to pass it to another endpoint you added it as an argument and the value was attached to the request (similar to the REST body). The receiving endpoint could then use that value from the request.
There were two distinct mechanisms depending on if the resource had a reference or a value on the requestors side - PUSH and PULL state transfer were both supported.
I think we must have felt this wasn't quite right since when we developed the NKF API we allowed the recipient of the request to treat the arguments uniformly no matter if they were PBV or PBR. In fact we had already established a broad point of principle in the architecture of ROC that informed many design choices...
Everything is a Resource
With this in our minds the receiving endpoint was required (via NKF) to interact with the PBV state by using the same resource addressing as for a PBR. No matter whether the request was PBV of PBR an argument was accessed like this...
foo=context.source("arg:foo")
[Actually for NK3 people it was context.source("this:param:foo") - different identifier, same resource!]
With the development of the general ROC abstraction of NetKernel 4 (and now 5) we introduced the concept of address spaces and decoupled the relationship between a module and its space(s).
Suddenly a wealth of new patterns were possible - imports, mappers, overlays etc etc - and furthermore, where an endpoint required configuration (such as a mapper config) then that too was a resource. Everything was a resource.
In this context, the distinction between PBV and PBR started to feel more and more arbitrary.
I can clearly remember Tony and I discussing the properties of the abstraction, attempting to reconcile this wrinkle.
We needed to think differently and I knew that Einstein made his breakthrough with relativity theory by posing a simple thought experiment: "What would the world look like if you sat on a beam of light".
We asked ourselves the same question: "What would the world look like if you sat on a request?"
The answer is quite enlightening. Rather than the request moving through the address spaces from endpoint to endpoint, the request remains stationary and the spaces move around you!
So then you think, when I want to pass-by-value why is that value not a resource? Everything must be a resource!
What would happen if instead of pushing state by shoving it into the request, we put the state into an address space and that address space could somehow "stay close" to the request?
Just as in the uniform approach offered by NKF the receiving endpoint would know the identifier of the state via its argument name. Only now instead of extracting the state out of the request, it would make a genuine resource request for the state and this would be resolved to the nearby PBV space. All of a sudden, everything (everything!) is a resource.
So that is what we did. It turns out to be incredibly simple and simplifying...
When you addArgumentByValue, NKF creates a unique identifier for the state, constructs a first class address space containing an endpoint that can resolve the identifier to provide the state. We call it a Pass-by-Value space...
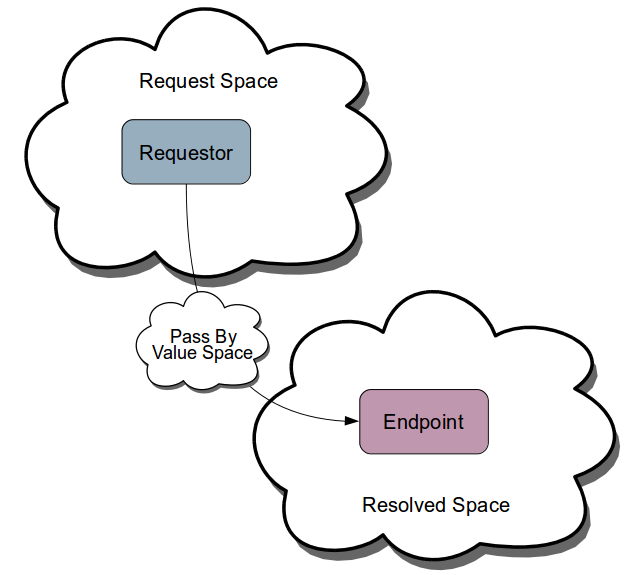
It follows that in ROC all state transfer is Pull.
Durable Scope
However there is one further innovation necessary. When you sit on a request, the spaces move and you stay still and so we require that the pass-by-value space must stay close.
What happens when an endpoint references the PBV resource but does not request it? That is, it relays (passes on) the identifier to the pass-by-value resource in a sub-request? It turns out that this pattern is a very common occurrence (again highlighting why Push is systemically such a poor choice).
Additionally what if the sub-request does not get resolved locally but is resolved either up or down the superstack? That is, the spacial scope of the request is dynamically changed (this is what we mean when we say the spaces move around us).
Well since the PBV state is uniquely identified there are no side-effects to it being present in the scope, so all we need to do is ensure that the PBV space "stays close".
We do this by marking the Pass-by-Value space as "durable" and whenever the Standard space resolves to a new endpoint, it respects Durable Spaces and retains them in the resolved scope close to the resolved endpoint.
We have not seen this elsewhere in computer science - we call it Durable Scope.
The Benefits of ROC Pull State Transfer
For all of the reasons that Push State transfer is a poor choice, ROC's Pull State Transfer offers very significant benefits.
The difference between directly accessing Push state, versus issuing a real resource request for the state as a resource is negligibly small - in practice a constant time lookup into a map with usually very few (often only one or two) entries. It follows that there is effectively no overhead for the Push-Pull inversion.
The benefits include:
- The state of the Pass-by-Value resource is reified Just-in-Time.
- If the resource state is never required, the reification cost is eliminated from the system.
- If the resource is to be used concurrently (for example a map-reduce style asynchronous process), the first executing thread can do the work to access the resource state and all subsequent threads get it for free.
- We can systemically cache all resource representations, irrespective of if they were computed from the results of other computations (pass-by-value). Everything is a resource, only the scope and the expiration model are determinants of whether a representaiton can be re-used.
This latter consideration allows us to discover "micro-caching" in which at a high-level (as with POST) we might not expect the final answer to be cached, but intermediate states are discovered and are frequently reusable for other macroscopically uncacheable requests. But even at a macro-scopic level, if the pass-by-value resource happens to be the same (something that does happen with real-world statisticial distributions) then we can retreive the answer from cache without computing it at all (with ROC we can cache a POST!).
Finally, it wasn't mentioned above, but Pass-by-Value in languages (and REST), assumes that the recipient of the state is encoded so that it is able to accept the structural representation of that state. We call this "typing". You can only pass state of the correct type to a given endpoint or function. Not with ROC!
The representation in the PBV space will have a given structure but if the receiving endpoint asks for it as something else (for example, DOM but the representation is a String), then since "Everything is a Resource" ROC will transrept the resource for us.
In ROC, PBV is inverted to first class PULL and the representation of the resource is decoupled from the endpoints.
The upshot is that ROC systems are completely decoupled and evolvable and the system's thermodynamic energy surface always sits in a local minima. Which translated is: its much faster and much more flexible to invert PUSH to PULL.
In ROC there is no Pass-by-Value. In fact, truly state does not move at all, spaces move and state remains stationary relative to a space!
Have a great weekend!
Comments
Please feel free to comment on the NetKernel Forum
Follow on Twitter:
@pjr1060 for day-to-day NK/ROC updates
@netkernel for announcements
@tab1060 for the hard-core stuff
To subscribe for news and alerts
Join the NetKernel Portal to get news, announcements and extra features.
NetKernel will ROC your world
 |