|

NetKernel News Volume 2 Issue 30
May 27th 2011
What's new this week?
- Repository Updates
- Backend Fulcrum Lock-Down
- DPML Internal Rewrite / nCoDE Update
- Hardcore nCoDE/DPML
- ROC Abstraction Consistency
- The Doctrine of Sufficiency
- Update to fileset
- Electron More Symmetrical than a very Symmetrical thing
Catch up on last week's news here
Repository Updates
The following updates are available in the NKEE and NKSE repository...
- lang-dpml 1.13.1
- Updated to a new implementation
- lang-ncode 1.2.1
- Updates to fix some initial release inconsistencies (see below)
- layer0 1.60.1
- added support for checkForBadExpirationOnMutableResource, refactored code for generating pbv: identifiers
- layer1 1.26.1
- Updated file: endpoint to accept file-poll-period header
- module-standard 1.43.1
- Added consistency check to StandardAccessorImpl (see below)
- nkse doc-content-1.28.1
- Updated docs for fileset
- nkse http-fulcrum-backend-2.2.1
- Added port binding configuration property (see below)
- pds-core 1.6.1
- Switched off consistency check (see below)
Backend Fulcrum Lock-Down
We received a useful tip from Jeff Hulten at Best Buy. He pointed out that Jetty's port binding in the backend fulcrum can be tightened up so that Jetty only binds port 1060 to the local loop interface (localhost, 127.0.0.1) and therefore is not accessible over any of the external network interfaces.
(If you have your own fulcrum, perhaps in a situation with multiple network cards, the detail is to explicitly set the "host" on a Jetty connector so that its binding is only to the matching IP address of the interface)
As with the port number (netkernel.http.backend.port), we've now made this configurable with a system property.
So, for example, with the installer you can limit it to localhost as follows...
java -Dnetkernel.http.backend.host=localhost -jar 1060-NKEE-xxxxxx.jar
For an installed production system you can add -Dnetkernel.http.backend.host=localhost to the jvmsettings.cnf file in [ install ]/bin/
As ever, one man's security is another man's grit, so we've made the default "0.0.0.0" (bind to all hosts) which is the same as previously.
To get this feature, accept the apposite update of the backend fulcrum, or its also slipstreamed into the NKEE download.
SSH Port Tunneling
Incidentally you might then ask how the heck do I control NK if the backend is only bound to localhost? Well we administer all our NK systems by using SSH port tunneling. For example this is how we connect to the virtual cloud server hosting the nk4um...
#!/bin/bash ssh -L 1067:localhost:1060 vm3.1060research.com
This is using ssh port forwarding to map the remote server's localhost port 1060 to the client-side port 1067 - we offset local port so that we can administer several NK's at once. So on the client side we just point a browser at http://localhost:1067/
DPML Internal Rewrite / nCoDE Update

The power behind the nCoDE visual composition development environment is the DPML language runtime. In nCoDE, what you wire up on screen gets compiled down and executed as DPML.
DPML is one of the ROC technologies that has been with us forever, indeed its very first implementation pre-dates NetKernel.
DPML is a way of writing compositions of multiple resource requests in a declarative syntax and supports both functional and sequential styles.
With each generation of NetKernel we've written a DPML runtime, and progressively evolved the language. DPML is interesting since internally it actually uses the ROC primitives of requests, spaces and identifiers as its fundamental building blocks. Therefore in its most recent generation it was actually written in parallel with, and informed, the NetKernel 4 abstraction and implementation.
However, the advent of nCoDE has enabled us to create much richer and much more complex ROC compositions and these highlighted a number of internal inconsistencies and inefficiencies in the implementation. In short it was out of date and had some holes and, with the benefit of four years of experience, could be implemented with more modern patterns and could exploit the newer foundations.
So since we got back from the conference and the public announcement of nCoDE, Tony has been locked away putting together a clean-room implementation of the DPML runtime which is now available.
These are the main features...

- Syntax and functionality remains unchanged except as noted*.
- Execution behaviour now follows best practice in terms of sub-requests and cachability. (Original DPML pre-dates completion of NetKernel4 kernel and used some experimental approaches that didn't stand the test of time).
- Visualization and debugging of DPML code is now much more straightforward, since it "feels similar" to what you might create by hand.
- All arguments are passed optimally as either pass-by-reference, pass-by-value, or lazy evaluated pass-by-request.
*Please Note: due to changes in the internal processing of arguments it was not possible to preserve backwards compatibility of the exception handling endpoint/tag in DPML. The following three identifiers that are used in referencing the caught exception have changed:
- arg:exception -> exception:raw - the exception caught
- arg:exception-id -> exception:id - the id of the deepest nested exception caught
- arg:exception-message -> exception:message - the message of the deepest nested exception caught
This naming change is consistent with other endpoints that inject representations into scope such as the new nCoDE forEach accessor. To convert your existing DPML scripts just do a global search replace.
You'll see below that DPML is now very solid and is able to consistently support the implementation of even hard-core recursive algorithms.
nCoDE
In parallel with the release of the new DPML implementation, we've shipped some fixes and enhancements to nCoDE.
In developing nCoDE it was discovered that common assignments within closures would be evaluated multiple times (if not pulled from cache) when referenced multiple times. This has now been fixed so that it is only evaluated once. This simple example...
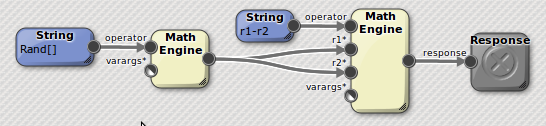
...shows how subtracting a random number (generated by a constantly changing random number generator) from itself should yield zero. However in the original implementation it didn't. This bug had broader implications for consistency across running processes and is now resolved.
A limitation in nCoDE was that dynamic imports, as specified in the settings of an nCoDE instance, were tied to specific module versions making forward migration difficult. Now, as is the standard convention of <import>, nCoDE uses the latest version of any particular module. Future versions may enhance the UI to support further versioning options.
Late in the optimisation process, just prior to the conference, the following bug was introduced into nCoDE: if endpoint grammars were edited but not saved then the input arguments into any references of that endpoint in other endpoints were incorrect. Validation and update of those inputs could not be performed based on the updated grammar until the whole instance was saved. This has now been fixed.
Hardcore nCoDE/DPML
So to prove that this is the best DPML ever. Here's a novelty item for you. This is the nCoDE for the Fibonacci double recursion algorithm...
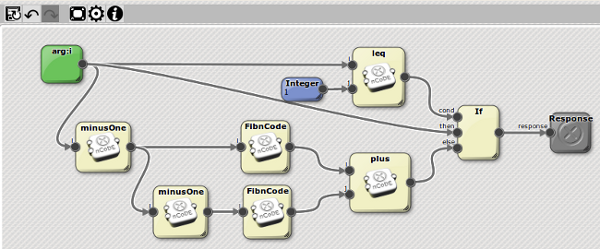
and, as with all nCoDE, is executed on the DPML runtime. Notice that it is doubly recursive (two requests to "FibnCode"), and that all its primitive operations are also endpoints implemented as nCoDE closures.
This is a particularly pathological test case since all the argument names are "i", which shows that the new DPML runtime is fully on top of argument scoping.
Finally, as has been our party piece demonstration for some time, this pure embodiment of the classically exponential double recursion algorithm, runs in linear time. Which shows that both the external results and internal state of the DPML executed process are real resources in consistent spaces and are cached.
You can try the demo for yourself. Here's a module, just add it to your modules.xml
http://resources.1060research.com/materials/2011/05/urn.com.1060research.demo.ncode-1.2.1.jar
When installed the demo runs from here:
http://localhost:8080/demo/fib/x - where x is an integer (keep it smallish <100 to avoid integer overflow)
Use the space explorer to find the nCoDE environment with this tool...
http://localhost:1060/tools/ae/view/allnCoDE
You'll see that res:/demo/fib/x is actually a front-end framework that allows you to switch between the pure nCoDE, a groovy based extrinsic recursive script and the MathEngine's fibonacci[] function. (Incidentally this last demo will require that you install the lang-math package with Apposite).
ROC Abstraction Consistency

There is an important and fundamental philosophy at the heart of ROC (and therefore innate to the design of NetKernel). The fundamental idea is that the meaning and validity of information is contextually relative.
By which, we mean it depends upon the interplay between the requestor, the requested endpoint and, since space is a degree of freedom, the spacial arrangement they instantaneously experience.
Identifiers
It follows that the kernel has no rules or knowledge of how you choose to identify your resources. To the ROC abstraction, identifiers are opaque tokens. Furthermore, an axiom of ROC is that, a resource may have any number of identifiers.
It follows that the requestor's conception of a given resource's identifier can be completely independent to the requested endpoint's idea. So, for example, what you're doing with the mapper is introducing a spacial construct to bind together two different world views about the identity of a resource.
When you first understand how ROC offers this level of freedom it can be a little daunting. But, to give ourselves some solid ground to work on, we adopt established conventions to make our task of choosing names feel almost automatic. So, we have the active grammar or, if you want to present a uniform address space out to the http world, you can use REST-path style standard grammars.
But never forget it is axiomatic that ROC ascribes no absolute meaning to identifiers.
Actually if this did not hold, it would not be possible to minimize the computational efficiency of a solution. Imagine, for example, if there were a central policeman enforcing arbitrary rules about the grammar and syntax of identifiers. It would be a terrible and dog-slow architecture. So as well as being fundamental to the ROC abstraction its essential for the efficient embodiment.
Spaces
We've also seen throughout this series of newsletters that address spaces are similarly unconstrained.
An address space is a system in which a request may be resolved. ROC says nothing about what that means or how it might be embodied.
For example, the web's ROC address space is the collected interplay of DNS, browser, network routing, port mapping and finally web-server.
Just as with identifiers, the kernel makes absolutely no judgement or asserts any semantics to spaces - they are systems to resolve requests and the kernel delegates all resolution to them. Again, this is not just a philosophical basis of ROC, delegation and decentralisation of resolution is essential for the optimally efficient embodiment.
But, as with identifiers, we provide a standard toolkit for designing ROC spaces - we call this the "standard module". But, just as with grammars, there's nothing fundamental about the standard module and there is no central policeman dictating a formal resolution procedure.
The fundamental nature of ROC is relativistic and its operational implementation and semantics is delegated to the interplay of the context of the requestor and the requestee.
Aggregation versus Registry's
One immediate caveat to this last statement, is that it gives you a pretty good yardstick to judge if a technology is normal and optimally efficient. If you find there is a central registry, then the architects have probably not got it right. It is invariably better that state should be "pulled and aggregated", rather than "pushed and centralized".
If you take a look through any of the system tools in NK you'll see a common pattern. For example the docs, the unit test system, the dynamic imports etc etc they all require a composite aggregation of the distributed state present in each of the system's address spaces. In each case, the tools perform a just-in-time pull-aggregation of this state. (FYI there's a useful accessor we wrote for this pattern - the active:spaceAggregateHDS in layer1.)
There are no registries in the NK tooling - even Apposite is a tool running off the transiently stored state of the pull-aggregation of the set of ROC address spaces represented by the repositories.
Incidentally this is why WS-* was always destined to fail and I lost no sleep over it 10+ years ago - as soon as you saw UDDI - you knew they didn't understand the Web.
Verbs
So I've been softening you up. What I really want to talk about is verbs and in particular the semantics of the verbs with respect to the longevity of representation state.
To set the scene for the discussion, here's a little snippet of script you can try in the scripting playpen...
boolean first = context.exists("file:/tmp/foo"); context.sink("file:/tmp/foo", "Hello World!"); Thread.currentThread().sleep(5000); boolean second = context.exists("file:/tmp/foo"); context.delete("file:/tmp/foo"); context.createResponseFrom(!first && second);
So imagine that to start with file:/tmp/foo does not exist. What is the boolean state returned in the response?
Firstly the EXISTS request will return false, so first==false. The SINK request creates the file and gives it the value "Hello World!". (Forget the sleep for a moment). The second EXISTS request now returns true, so second==true, so the response is !false && true==true.
OK now try commenting out the sleep. False!
What the heck...?
Delegated Consistency
What you just discovered is, by default, the endpoint for the file: address space uses the system-wide "Filesystem Poll" to introduce hystersis in the expiration function for SOURCE,EXISTS representations from the file system. It does this since polling files is a potentially expensive operation, so it introduces a Nyquist sampling rate, which in most circumstances is sufficiently accurate at reflecting the underlying state for general use.
In the first case, the sampling rate was (deliberately) within the Nyquist criterion and so we seemed to get consistent results. In the second case we were sampling the state of the file (re-requesting EXISTS) in a time much shorter than the poll period and so we hit the cache and since the expiry function hadn't yet tried to poll the filesystem we got what appeared to be an inconsistent result.
Now, if you are writing something that uses files and really need to have fast-correlation between the state of the system and the state of derivative resources then you can either turn down the global poll interval, or (better), specify a specific polling period as a request header. Like this...
import org.netkernel.layer0.nkf.*; req=context.createRequest("file:/tmp/foo"); req.setVerb(INKFRequestReadOnly.VERB_EXISTS); req.setHeader("file-poll-period", "0"); boolean first=context.issueRequest(req); context.sink("file:/tmp/foo", "Hello World!"); req=context.createRequest("file:/tmp/foo"); req.setVerb(INKFRequestReadOnly.VERB_EXISTS); req.setHeader("file-poll-period", "0"); boolean second=context.issueRequest(req); context.delete("file:/tmp/foo"); context.createResponseFrom(!first && second);
...which specifies a file-poll-period of zero, which means the underlying filesystem will be tested every time the resource, and any of its derivatives, is tested for expiry.
(Incidentally, please make sure your layer1 is up-to-date for this feature)
Now, forget the detail of this file: endpoint, I've just been doing even more softening up.
The point we're ready to make is that: the consistency of state produced by an endpoint is the responsibility of the endpoint.
The kernel (and indeed the ROC abstraction) has no prescribed expectation of what constitutes consistency in representation state. The only thing that the kernel knows is that a resource has an expiration function - and before it serves something from cache it checks to see if the resource is not expired.
So now imagine that you are implementing an endpoint that implements SOURCE, SINK, DELETE, EXISTS.
If you SOURCE a resource from the endpoint, then SINK new state, is the old state expired? What if it would be incredibly expensive to recompute the state for a SOURCE on every SINK, and Nyquist sampling rates are adequate for your system?
What does EXISTS mean? For a Platonic resource set, like the Fibonnaci series, you could say that:
EXISTS fib(x) == true ∀ x
You will almost certainly have particular semantics for EXISTS for your resource set. (What about EXISTS God? Hmmmm, that's certainly relative to your perspective!).
The fundamental nature of ROC is relativistic and its operational implementation and semantics is delegated to the interplay of the context of the requestor and the requestee. - this holds for verbs, and more particularly, consistency in expiration determinant.
This shouldn't really come as news - the fact that the NKFResponse has setExpiry() implicitly raises the expectation that you, the endpoint implementer, have been delegated the responsibility for maintaining consistency. Where "consistency" is a relative concept related to the resource set that you are providing access to.
Safety Net
Now there's nothing like semantic consistency with respect to verbs to get people worked up. Even though, as I hope I've illustrated, its just another aspect of federated delegation innate to the ROC abstraction. And, equally, if there was a central semantic policemen in the kernel the system would be dog-slow and innefficient - but worse still, it would be wrong and exclude many many legitimate systems.
However, with all that I've said, if you're not immersed in ROC, you might still feel "uncomfortable". Surely a SINK should expire a previous SOURCE?
Tony has argued that it is unnecessary and adds inefficiency to provide any constraints in the infrastructure to bound the semantic consistency of the state with respect to request verbs. He's actually completely right - as usual. However, after some heated discussion, we worked out a compromise.
The update to standard-module has added a new safety net feature to the StandardAccessorImpl. It now has a new check on a response as follows...
If you implement onExist and/or onSource and also implement onDelete, onSink or onNew, and your response has the default expiry determinant, then we will issue a warning to the logs - saying you may, possibly, not be fulfilling your obligation to maintain consistency in your representation state.
However, as I've hinted, there are many legitimate situations where the default dependent expiry is perfectly valid, for example what if you are using the golden thread pattern? In which case, we've given you the ability to assert your supremecy and disable the safety net. In your accessor's constructor you can call:
declareInhibitCheckForBadExpirationOnMutableResource();
So, for example, today's update to the pds module was simply to disable a false positive warning from the new nanny! (Doh!).
The Doctrine of Sufficiency
As you'll see in my science article below, the basis of ROC is that, in real world information systems we cannot (indeed are wrong to try to) assert absolutes. To my eye, part of the problem of software system's historically has been the expectation that software is absolute, deterministic and that "code is analytic" and so must reflect an absolute.
I don't see it this way. I see historical software as a recipe for brittleness and inefficiency.
I see computation as measurement. The role of the software architect is to set up "the experiment" and introduce constraints, such that the system's measurement of the representation state is "sufficient" for the problem at hand.
Excessive precision costs energy and sets the system in stone. Take care.
Update to fileset
Incidentally one of the updates to standard module that shipped before the conference was that the <fileset> now has the option of being made mutable. Unfortunately in the rush, its documentation wasn't updated - but that's been fixed in today's update to the nkse-doc package.
Mutability means it can optionally support SINK, DELETE verbs. So you can SINK to res:/my/path/foo. Since the fileset is backed by the underlying filesystem, this feature only works for expanded (not jarred) modules. But it also comes with an expectation of management of consistency. It follows that a mutable fileset has an associated poll period - which may also be specified. Here's the docs...
Poll Period
By default resources requested from a fileset will have caching dependencies which depend on the underlying file resource - however it is potentially expensive to monitor files in realtime for changes - therefore by default the fileset is polled based upon the system-wide file polling interval specified in the kernel.properties (and which may be set as "Filesystem Poll" with the kernel config tool).
Any use of cached file resources in a time period shorter than the poll-period may potentially yield inconsistent results.
If your application requires very precise correlation with the realtime state of a file you may declare a specific poll period on a fileset declaration. In this example the poll period of zero will ensure that all derivative resources will be tested directly with the underlying file on every request.
<regex>res:/directory/path/.*</regex>
<mutable>true</mutable>
<poll>0</poll>
</fileset>
Electron More Symmetrical than a very Symmetrical thing
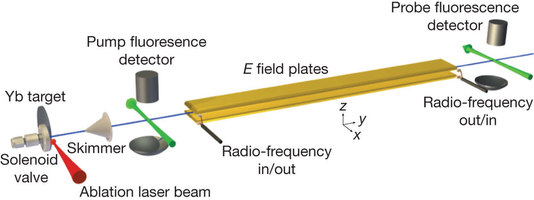
This week's exquisite measurement is that, to very high precision, the electron (specifically its electric dipole moment) is spherically symmetrical.
Its a beautiful experiment where Hudson et al used circular polarised laser light to align the electron spin then passed the aligned electron beam through a long uniform electric field. The field bends the beam, any dispersion of the beam at the detector shows the asymmetry in the electron electric dipole moment. There are a lot of details and experimental consistency requirements, but its very elegant and relatively cheap and simple, and eminently reproducible.
The significance of this result is that some of the leading theoretical contenders challenging the standard-model predict that it ought to be non-spherical well above the scale that has been measured.
Here's how science works. As a theorist you can now do the following:
- Contest the measurement and assert that it has insufficient resolution, or has fundamental false assumptions.
- Encourage other groups to repeat the measurement or devise higher resolution techniques in the hope that this will put you back in the game. (Don't hold your breath here though, the title of the new paper is "Improved measurement of the shape of the electron" where Improved suggests that this group is not alone and is part of a general push to ascertain knowledge about the measurable properties of the electron - incidentally the Imperial College team believe they can go 10x better with progressive refinement of this technique).
- Rethink the basis of your theory and understand how/why its predictions are not manifest at the scale you predicted - ie refactor and feedback the measurement into your model.
- Fundamentally question your own assumptions and challenge yourself, if you, in fact, have an inconsistent world view.
And so it goes. Measurement and theory in an eternal dance - we accept that we can never reach absolute answers, but just like with infinite monkeys typing Hamlet we can most assuredly build up a body of evidence that has such a low-probability of uncertainty that we can stand on the ground and move forward. This is how we make sense of the world.
As we saw recently with the measurements of gravitational frame-dragging, its a great time at the moment for science. Not least in that the world hasn't ended and maybe, just maybe, some deluded people will start to ask themselves if perhaps a rationalist mental-model of the world might not be more useful to them.
I'm quite liberal minded. You can believe what you like. But for your own sake you should be consistent. If for example, you belong to a cult such as creationists, which fundamentally rejects the accumulated rational position on evolution, then you are at odds with the modern world's interdependent rational belief structure. Significantly, the rational world is made concrete by its manifest embodiment as the very basis of our everyday technological landscape. If you really hold to your belief that is fine, just please do not undermine it by using the biproducts of rational belief viz: medicine, electricity, sanitary water, television, radio, heating, air-conditioning, computers, internet, cellphones, telephones, aircraft, cars, trains, bicycles, ipods, ipads, man-made-fabrics, velcro, plastic,... oh yeah... food packaging and, indeed, most foodstuffs. For surely, to utilize such technologies is a tacit acceptance of the N-fold interwoven fabric of rationalism, including that small corner for which you claim to hold a valid alternative belief...
Have a great weekend,
Comments
Please feel free to comment on the NetKernel Forum
Follow on Twitter:
@pjr1060 for day-to-day NK/ROC updates
@netkernel for announcements
@tab1060 for the hard-core stuff
To subscribe for news and alerts
Join the NetKernel Portal to get news, announcements and extra features.
NetKernel will ROC your world
 |