|

NetKernel News Volume 2 Issue 20
March 18th 2011
What's new this week?
- Repository Updates
- Thoughts on Japan Quake
- Correspondence from the Marshall Islands
- *New* SSH Client Library
- Pattern: Avoiding "Filesystem Leaks" with TransientFileRepresentation
- Over the Shoulder view of the ROC Development Process - Part 1
- Beer Review: Orval, Trappist Belgian Beer
- Bizarre Coincidence
Catch up on last week's news here
Repository Updates
The following updates are available in both the NKEE and NKSE repositories...
- layer1 1.23.1
- Adds the new TransientFileRepresentation (see below)
- ssh-client 1.1.1
- A new ssh client library (see below)
Thoughts on Japan Quake
I'd prepared the bulk of this newsletter in advance ready to post it last Friday, the 11th March. That morning, I got into the office about 8am UK time, checked the news and learned about the quake, which had happened about an hour earlier.
Like many people, I sat transfixed and numb as I watched the live helicopter images of the engulfing tidal wave. It was all too obvious that what was unfolding was a dreadful tragedy.
My usual task on Friday morning is to wrap up the newsletter and, as I hope comes across, I try to make the content interesting, humorous and upbeat. These newsletters now get quite a large readership many of whom I've been fortunate enough to strike up personal friendships, beyond mere "technological-bonds". So, it follows, I am very much aware that when I send out the newsletter it goes to all corners of the world.
So last Friday morning, while the Tsunami was scourging Japan, it was unknown if the wavefront would travel out and affect the rest of the Pacific basin.
I was acutely conscious that there are ROCers in Japan and even among some of the remotest regions of the Pacific basin - even, for example, providing meteorological services to the Marshall Islands (average altitude 1m above sea-level) and agricultural resource tracking in Vanuatu.
It was inconceivable to send out the usual ping from "chirpy Pete".
My thoughts were elsewhere and as the afternoon progressed, in a trivial way, stirred into action to work out if there were any critical NK-support related measures we could take or offer to those in the region (there weren't, but you do what you can).
One small consolation, after about 8-hours it began to emerge that the Tsunami's energy was dissipating and so was unlikely to lead to significant damage to the broader Pacific rim.
Sifting for Positives
It was bad, and there's no need for me to belabour the horrors of the quake, the regular media has provided all the mawkish details. Days later its still bad and it will take months and years of determined effort to start to recover. We would not be human if we did not have the deepest empathy for the tragic loss and suffering.

But, being positive in outlook, I find it hard not to try to look for something uplifting in all of this. The non-technical media seems to have missed a remarkable facet of the events.
Its best captured by this simple, but nevertheless amazing, tweet by a local resident at the epicenter...
"Despite the magnitude of Friday's earthquake it is difficult to find signs in Fukushima city of how viscously the ground moved. Most damage seems to be limited to free standing walls bordering properties that were not reinforced".
Wow, read that again: "it is difficult to find signs in Fukushima city of how viscously the ground moved".
The entire North-Eastern region of Japan was subjected to the 5th largest earthquake ever measured. Outside of the narrow coastal Tsunami zone, for which frankly, we just do not have the economic means to protect, fundamentally the buildings, the bridges, the telecoms systems, the electricity supply, even in places the gas supply... the core infrastructure endured.
It is, unfortunately not the case with the Nuclear reactors at Fukushiwa. Its too early to tell what series of design measures could have prevented the seemingly extreme series of misfortunes. Although the media love to sensationalize, its likely the outcome will be managed and, even in such terrible circumstances, conclude by having a relatively limited long-term effect - we can hope.
Co-incidentally, before the quake and reactor situation, for the unpublished news I'd prepared a frivolous article (last item below) on my experiences of high-pressure, must-work, "big-engineering". But even though I've had a little experience of exploring the extreme limits, and even ironically as discussed below, on a very much smaller scale, of extreme thermal management to prevent explosive meltdown; I can't even guess at the pressure the Fukushima reactor crew have been under and the depths of courage they have drawn upon.
But the optimist in me cannot help but take comfort in one remarkable positive: how much worse it could all have been in the wider region but for systemmic resilient engineering.
To the engineers of Japan: We salute you.
Correspondence from the Marshall Islands

|
Being a physicist means you've got no place to mentally hide from the stark realities of the physical world. Waves, even big waves, obey simple rules. As is graphically illustrated in this email correspondence with Mark Bradford, Chief Meteorologist of the Marshall Islands (highlighted region in diagram, and on a line perpendicular to the mainland of Japan). Mark's a dedicated ROCer of many years standing, I asked him if I could quote this verbatim... |
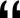
Hi Peter, Thanks for the message and your thoughts. As the Chief Meteorologist here, I was right in the middle of the event. The only quantitative info we had before making sheltering decisions was a +/- 2 meter amplitude forecast by the JMA before Japan went completely off the air. Our fiber runs through Japan, so it was down and we were on backups (e-mail has been slow). Just a regular day, followed by a tsunami night, several hours of sleep, then morning warning supplements. We actually had a tsunami here, the ringing (which you, as a physicist, understand) of the ocean is readily apparent in our tide gauge plot. In last year's Chile earthquake and tsunami, we got no easily detectable signal. In the 1960 Chile earthquake and tsunami we got about 8 cm of amplitude. With this tsunami we got +/- 55 cm and still ringing 16 hours later. The low amplitude was enough to set boats on the marina floor (low tide and -55 cm on the tsunami troughs). I've attached our tide gauge plot, it might interest you from a "wave equation" perspective. In the north part of our lagoon, near the passes exposed to the tsunami with less wave interference, the effect was even stronger, but, alas, no are no measurements there, just mariner's anecdotes. Ciao, Mark Mark Bradford 
Peter, Sure, go ahead and use the graphic and post. It is just good to communicate with someone who understands waves. Just a little more about the figure: The blue curve is the predicted astronomical tide. The red line is the measured tide from the gauge at Echo Pier in the Kwajalein Lagoon (not oceanside). The green curve is the residual, initially showing a 6" sea level rise due to La Nina, but smooth since wind waves and swell have little power. Then the residual shows the incredible power of the tsunami. At Kwajalein we've never seen residual amplitudes like this, for the American Samoa (Sep 2009) and Chile (Feb 2010) tsunamis you could not detect a tsunami signal here above the wave/swell noise (although you could clearly see them on the Hawaiian gauges). The good news is we have lots of two story concrete/rebar/cinderblock structures here so we can go upstairs and shelter. The bad news is for the outer islands, with no such structures, they always take the brunt of typhoon and ocean swell waves. There are no reports of significant damages here, even on outer islands. Usually a tsunami does little to these islands since our bathymetric terrain slopes at 45 degrees with no shelf, so we get negligible wave amplification like you get with a continental shelf. The fear is that one day there will be a 4 meter open ocean tsunami slamming down on our little 3 meter-high island at 250 m/s. Knock on wood. Ciao, |
For me these observations, in the context of historical events, highlight the relative magnitude of the Japan quake and, in my mind, only serves to reinforce the positive nature of the engineering accomplishment outlined above.
Life must go on. And so, with all too raw self-consciousness, your normal chirpy service resumes...
*New* SSH Client Library
The new ssh-client library in the repositories provides a comprehensive set of client tools for SSH access to a remote server.
Tools are provided both as active:sshXXXX services and as a general ssh:// scheme supporting SOURCE, SINK, DELETE and EXISTS verbs.
Here's an example (declarative request) showing how you can use active:sshGet to transfer a file from a remote server and use its representation in the ROC domain...
<identifier>active:sshGet</identifier>
<argument name="remote">ssh://my.server.com/path/path/path/file</argument>
<argument name="credentials">res:/resources/my-server-ssh-credentials.xml</argument>
</request>
Here's how to do a traditional remote-to-local ssh file copy...
//Source remote file representation rep=context.source("ssh://my.server.com/path/path/path/file") //Sink to a local file URI context.sink("file:/home/pjr/file", rep)
and here's a bizarre example, how to save an RDBMS query to a remote ssh file...
//Construct and issue sql query req=context.createRequest("active:sqlQuery") req.addArgumentByValue("operand", "SELECT * FROM sometable;") rep=context.issueRequest(req) //Sink result set to remote ssh server context.sink("ssh://my.server.com/path/path/path/file", rep)
Notice that the remote ssh accessible resource is referenced with a URI using the ssh:// scheme which supports a range of Verbs. (When using the ssh:// scheme endpoint, the credentials are sourced from the resource res:/etc/SSHCredentials, which you must implement in the spacial context.)
Remote Exec
Remote processes may be executed on the remote server with the active:sshExec accessor. The stdout of the remote process is returned as a resource to the ROC domain, so allowing the results of remote processes to be incorporated into an ROC solution.
Here's an example (declarative request) which would show and return as a IReadableBinaryStream representation the remote Unix system's uptime...
<identifier>active:sshExec</identifier>
<argument name="command">
<literal type="string">uptime</literal>
</argument>
<argument name="remote">ssh://my.server.com</argument>
<argument name="credentials">res:/resources/my-server-ssh-credentials.xml</argument>
</request>
Here's how a master NetKernel instance running on one server could use ssh exec to start a NetKernel daemon running on some other server (provided you have exec permission for the daemon script!)...
req=context.createRequest("active:sshExec")
req.addArgumentByValue("command", "/etc/init.d/netkerneld start")
req.addArgument("remote", "ssh://my.server.com")
req.addArgument("credentials", "res:/resources/my-server-ssh-credentials.xml")
rep=context.issueRequest(req)
Large Files
Large files are supported. The library is written to use local file buffering for all ROC domain IReadableBinaryStream representations (both get/put and exec resources). Therefore ROC process do not need to be concerned with the size of the transferred files since they are not held in the JVM memory.
Pattern: Avoiding "Filesystem Leaks" with TransientFileRepresentation
The ssh client tools buffer all of the wire-level state to the filesystem so that there is never any need to hold the resource representations as ByteArrays in the Java heap. It then allows the ROC domain to use the state as IReadableBinaryStream representations backed by the buffer-file.
This is a useful pattern and it is also used, for example, with the NKP protocol to allow you to transfer arbitrarily large resources without blowing up the heap.
The technique makes use of Java's File.createTempFile(). Of course we only need this file for as long as its useful. So we can clean it up later by using Java's File.deleteOnExit() - so the temporary file gets cleaned up when the JVM system exits...
Hmmmm. Our aim is that NK should never stop. The JVM should never exit. Hmmmm, Java will never clean up for us. Problem!!!
If you just worked with Java's knowledge of the world, you could, with a long-lived server, easily fill up the filesystem with temporary files.
OK, so on your development machine you have a huge disk. But what about a virtual server running on a virtual disk? Its pretty common to have a disk image of 4GB. You could fill the disk and inadvertently cause a nasty failure mode in your system. We call this scenario a "Filesystem Leak".
Typically, with regular classical Java, the best you can do with a scenario like this is to guess some arbitrary time interval and dedicate a thread to go and clean up the "garbage files" every so often. That's as good as it gets and there's no knowing if those files are actually still part of an active process? Anything more sophisticated rapidly starts to get complicated to manage this local temporary state.
ROC Automatic Leak Prevention
Fortunately in the ROC domain, we always know what state is useful. Either we currently are processing it and so have an object reference to the representation, or when its returned in a response representation we keep a reference to it in the cache. If nobody cares about this state, it doesn't make it in the survival of the fittest contest and eventually gets ejected from the cache, at which point we let the JVM do a GC on the representation.
Ah Ha! If we had a file-backed IReadableBinaryStream representation, that deleted its backing file when it was finalized, we could automatically prevent filesystem leaks. This would work because in ROC we really know when something is useful and also when its not.
And so, we introduce org.netkernel.layer1.representation.TransientFileRepresentation. Which you'll find in the layer1 module and which is an implementation of IReadableBinaryStream backed by a file, and which will delete the file when its finalized.
Here's how it's used in the ssh tools...
File f=File.createTempFile("nk-ssh", null);
FileOutputStream fos=new FileOutputStream(f);
scp.get(aURI.getPath(), fos);
fos.flush();
return new TransientFileRepresentation(f);
If ever you need to buffer resource state to the filesystem, you can use the TransientFileRepresentation to be able to seamlessly use it in the ROC domain, and when its truly no longer useful it cleans up after itself.
Over the Shoulder view of the ROC Development Process - Part 1
As I mentioned last week, I recently spent a week in Belgium. Its always a good thing to do some teaching as it gives you a fresh perspective, and as I discussed last week its interesting to observe the default working practices of someone coming to ROC from classical development.
When I do training I like to get the taught material behind us, and really start to apply it to a relevant domain problem for the particular class. There's no substitute for experience.
So at the start of the final day, the Steria team proposed a simple but relevant use-case for an exercise. As often with such things, we ended up only having just a couple of hours to design, partition and assign teams to get something done, and by the close of the day we ended up with the basic foundations of a solution.
I wanted to show some specifics like the use of the pluggable-overlay and the transaction overlay (see last week) but we ran out of time, so I took it on to return home and fill in the details, with the aim of delivering the completed exercise as a more complete example.
On my way home, I was thinking about the dynamic nature of ROC and the rapid verification techniques you use (which I discussed extensively last time). I realised that it would be pretty useful to carefully capture the step-by-step details of how an experienced ROC developer would solve a problem. So rather than just fill in the missing pieces as I promised, I decided to start from scratch, to document the full cycle.
So, with kind thanks to Steria Benelux for releasing this material, here's the first part...
Use Case: Broad Specification of the Problem
The Steria guys explained an architecture that was relevant to one of their customer accounts. A message processing system, with transformation, persistence, and mandatory audit requirements.
Broadly speaking XML documents would come in via REST (and other protocols), the messages needed to be processed, persisted, a new message document constructed and returned as the response to the service user. It was essential that every inbound and outbound message was audited with a logging service. Also the system needed to shout out if anything "unusual" happened, so it needed an alert system.
That was the basic outline, it wasn't feature complete it was just an exercise that had some degree of real-world relevance.
So, the first job is to broadly specify the problem: time for a whiteboard and some boxes. So we quickly sketched up a diagram like this...
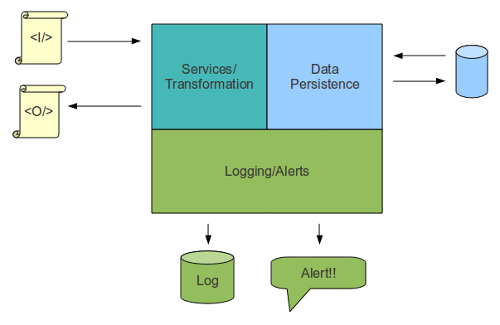
The problem naturally partitioned itself into three separate parts. The front-line services and data transformation, the persistence and data access and the logging and alerting infrastructure.
With parts boxed up, we could see that a natural division of labour follows. We didn't need Durkheim to work out that three teams could take responsibility for a chunk each.
So we split the class into three groups:
- Team A, the front-of-house crew.
- Team B, the data jockeys
- Team C, the unsexy but essential auditors and fire-brigade.
Focus on the Boundary Conditions
So the next task is to look at the problem with a "resource oriented" perspective. As ROC architects we have no interest in the internals of the boxes. All we care about are the boundaries.
For terminology sake lets assume that a requestor is always "UP" (ie calling from "up-stream") and a provider of resources is "DOWN" below us somewhere. So any given space has two relevant edges its TOP and its BOTTOM.
So now as an owner of a box I can ask the question: What resources am I promising (TOP), what resources do I need to deliver my promise (BOTTOM). I can work from both edges towards the middle (if we're lucky there is no middle).
So with an ROC perspective we can look at our architecture like this...
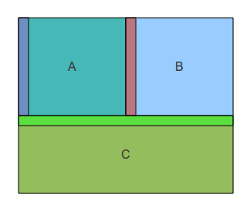
The relevant edges are the RED, GREEN and BLUE regions marked.
Time to get Talking
So the next task is to decide who needs to talk with whom? This ain't technology - so far we've not gone near any code or built a thing. This is about the necessary discussion between the teams.
So we quickly realise that team C, the Auditor/Fire Brigade, offer services to everyone. So, apart from a nod and a wink to Team A about the form of the raw messages which have to be logged, they can take all responsibility for their TOP interface. When they've worked out a first draft of the services and grammars they can cut a copy and give it to A and B to issue requests against - it won't be live but it'll solidify the boundary layer. So team C can immediately be released to start work.
Team A has the key promises to deliver - their TOP surface is the BLUE boundary, the services that will be required by the end-users. But they also have a bottom, the RED boundary and so they need a good working relationship with team B.
Team B are subservient, their only role is to satisfy team A and to call the fire-brigade (C) if things go wrong. But, while they are told what to do, they ironically have the most freedom - they are complete masters of the persistence layer, they can implement it anyway they like provided that they can satisfy the resource criteria of team A.
Team A needs to talk to its end-users. What state are they delivering, what do they want doing with it and and what do they want back in return? Team A probably has something of a broad idea - else they'd not have won the contract (or been assigned the project) so they can give a broad heads up to team B. So even with no details B can set to work sketching up the broad-brush interfaces that A has discussed with them and designing the database schema etc.
No Coupling
At this point ROC's dynamic compositional loose coupling starts to naturally complement the development process.
There is no need to link any of the physical development units together. Each team can decide their own physical partitioning, based on the anticipated lifecycle of the internals of their black-box. Its nobody's business but their own how many modules they have or what goes in them.
The project looks like this:
- Team C is away defining their interface and mocking out implementations and is out of everyone's hair (As it turned out they did what auditors always do and started to get ideas of total world domination. They implemented a logger in a matter of minutes, but then decide that they were going to create a transparent architectural layer to sit in front of the BLUE boundary layer which would transparently log all inbound and outbound messages - their so called "spyLogger". No matter it doesn't affect A or B in any way and can be independently worked on).
- Team B is knocking up a candidate TOP spacial interface and will almost certainly think of something relevant to the solution that will inform their internal persistence and also feedback to A to help them decide details of what they really need.
- Team A can work out a candidate interface while sitting down with the end-users and can plan the transformations and necessary resource requests to team B at their BOTTOM edge.
Each team works independently and simultaneously on each of the boxes.
At this point Teams A, B and C are just using the grammars, maybe the mapper and some of the tooling of NK to provide a fluid and dynamic compositional environment - no code, all architecture.
Notice we've not got hung up on any philosophical worries about "sets and resources". Don't get me wrong, the teams are working with sets and resources, its just that their focus makes that irrelevant, the abstraction is quietly doing its thing in the background, but it doesn't affect the first order task of defining and satisfying the boundary conditions.
Next time we'll start to look at the details of the RED, GREEN and BLUE boundaries and see how the three teams can provide scaffolding for each other to accelerate the parallel development.
In the next section you can see how I got to this point with my own schizophrenic development exercise...
Over the Shoulder Impl
I've posted a zip file containing a commentary.txt file which is a rolling diary of exactly how I went about implementing the first stages of this project. (In the class we'd done the design exercise I outlined above, so that's not repeated, this is "the getting down to it" material). You can get it here...
http://resources.1060research.com/docs/2011/03/steria-training-project-part1.zip
The commentary is broken into phases and looks like this...
Steria Project Development Commentary PJR 27/2/2011 ==Setting Up== 1. Create template modules with new module wizard for service, data and logger modules. Only take basic default settings don't connect to any fulcrums - so far these are simply independent libraries. 2. Copy and paste each module directory and clone with name test.x.x.x.x/ 3. Edit module.xml in each of the test.x.x.x modules to make its name test:x:x:x. Also remove first rootspace leaving just the unit test rootspace. 4. Edit module.xml of the main x.x.x.x modules - remove unit test space as its now in a clean separate module. 5. Start with a clean slate. Remove all the boilerplate content of the rootspace of the x.x.x.x modules. 6. Copied and pasted the <module>x.x.x.x</module> entries in modules.xml and prefixed with test.x.x.x to deploy the unit test modules to the system. 7. Checked the system deployment report to see all is healthy. Used space explorer to see all six project modules are present and correct. 8. Ran all unit tests - see that my default wizard tests are failing (not surprising I removed all the structure from the rootspaces!). So edit testlist.xml in each test module to assert <exception/> ie test is there but I acknowledge that at this stage it should be broken! Now all my unit tests are passing. Total time: 5 mins Package of this state: steria-project-0.0.1.nkp.jar PJR Comment: At this point the individual parts of the system could be developed in parallel - but since I am single cored I did the following as a series...
After each phase I note how long it took and I also take a snapshot of my development - this is a NetKernel package containing the instantaneous state of my development modules. There are six phases in this first part, so six packages.
The way I suggest you use these is to unzip the archive and then use Apposite's "upload package" feature to install the first 0.0.1 version of the package. When you've looked at it you can rollback and then install the 0.0.2 etc. Note you must rollback before installing the next version, since these packages are not in a repository and you may end up getting confused with multiple instances of the same modules. (Apposite uses the repository as the source of metadata for contextualizing package dependencies etc.)
You should be able to easily see the steps I took. The one thing I would repeat from last week, notice how I keep checking whenever I make spacial/structural/architectural changes. NetKernel is a live dynamic system - it is at the extreme limit of "loosely coupled" - so its important to take small and verifiable steps with spatial consistency. Once you've put in place a spacial change it will become very robust and live for a long time. So this is a progressive approach and leads to the natural emergence of large scale complex architecture.
Adding my "commentary" was pretty labour intensive. However the aggregate real development time to get to this point was about 30mins (perhaps less if I didn't have to context-switch to keep taking the notes on what I'd been doing).
You can see that I'm doing this work serially but the modules are very amenable to parallel development and so the development could readily be load balanced across a "multi-core" development team as outlined above. Its not uncommon that a team with regular day-to-day NK experience would be able to parallelize a project like this down to total of about 40mins including tests and some documentation for a first level functioning proof of concept.
One of things that also becomes clear with a little more experience is that any functioning spacial arrangement is a solution to the problem, and therefore it does not need reimplementing to move into production. Furthermore, once you have a solution in place, it is very cheap to evolve and enhance it without disturbing the existing capability.
Next week there'll be the details of how the boundaries are developed.
No substitute for experience
We regularly hear from new ROCers who have boot-strapped themselves into the ROC world by downloading NK, trying the demos and tutorials and reading the docs. But to get from this point to solutions and evolvable systems, there really is no substitute for experience - there are so many patterns, techniques and elegant solutions to problems that come up by learning to think and work "resource-oriented".
Experience grows naturally by experimentation and day-to-day useage, but it can be dramatically accelerated with some training from the experts (viz-a-vis us).
In a training course we take a team through the mechanics of the ROC learning curve in a couple of days. We then like to spend another day (ideally two) actually defining and working on real problems (exercises like I showed above). Its this latter phase which "can't be learnt in books".
But don't take my word for it...
|
The best place to learn French is France, the best place to learn Resource Oriented Computing is Netkernel. Netkernel is an environment where you are able to think in resources and relationships between resources. This complete submersion in the world of resources enabled us to change our viewpoint on software development. ROC is the future of IT.* Thanks to the course, this only took 3 days.
René Luyckx, CEO of Steria Benelux (who took the class alongside his team)
* René asked me to point out this is his personal opinion and not an official statement by Steria.
|
So, if you're exploring NetKernel and ROC, and really want to experience it for real, we're ready and waiting to take you to the next level...
Hey, who knew marketing could be so uncomplicated: simply stand on a corner and shout "buy this stuff, its good, you'll like it", stand back and wait for the stampede. What? It doesn't work like that!?
Beer Review: Orval, Trappist Belgian Beer

Every now and then you discover something good and wonder why it took you so long to find out about it.† I recently had this experience.
On my recent trip to Belgium I was introduced to Orval, a Trappist beer. It shouldn't have taken so long, since I'd studied Belgian beer extensively as a core part of my PhD research...
The quantum mechanics effects I was researching were in solid-state semiconductor devices*. They required very extreme conditions: 30 mK temperatures and 30 Tesla magnetic fields.
As of this date, there are only two known places in the universe with these conditions, the one I had access to was a 1-cubic centimeter space in southern Holland (FYI, the other is a similar size space in Boston at MIT).
So I had the great opportunity to spend extended spells working at the High Field Magnet Laboratory at Nijmegen Unversity in Holland.
30mK (30 thousandth's of a degree above absolute zero) is routine in research labs. All you need is a Helium-4 liquification plant, a few litres of Helium-3 (an isotope of Helium that is missing one neutron - which makes it so light that any naturally occurring He-3 just drifts off into space; Helium-3 is very rare and very expensive: the only reliable source is as a bi-product of nuclear reactors), a cryostat (flask) and some killer plumbing, in the form of a dilution refrigerator.
But serious magnets require serious engineering. To get the very highest fields you run a low-temperature (4K) superconducting magnet inside a Bitter magnet - this is tricky stuff, their natural inclination is to explode with the stress.
A Bitter magnet, is not superconducting, its just a really really big electromagnet which uses lots of electricity: really really a lot; 20kA currents are typical. This current goes through a large stack of copper discs that really don't want to be conducting so much current; they'd rather be a puddle on the floor. To persuade them to stay solid requires lots and lots of high pressure iced-water.
I discovered that the people of Holland are quite keen on electric lights, cookers and the odd spot of television entertainment. It follows that they don't like it very much if you divert the whole town's electricity supply; even to temporarily create one of the rarest places in the universe! So to keep everyone happy, it was necessary to run the magnets at night.
Usually I'd spend all day in preparation and be able to start the experiments at 11pm.
Electricity is relatively abundant, especially if there's a small nuclear power plant down the road. The problem was the iced-water. You see every day a refrigeration plant would freeze a quantity of ice needed for the cooling. But here's the rub; to run the magnets at their highest field for half an hour consumes a block of ice the size of a couple of standard domestic houses. That's a big ice cube.
Depending on how much high-field running I was doing, this could mean that you could use up all the ice by 3-4am. No ice. No magnet.
What's a young fellow supposed to do now? Go to the pub of course...
And so, from 4am until approximately breakfast time, myself and an assortment of my Dutch night-shift colleagues would find ourselves at a very civilized and very pleasant local bar in a local neighbourhood of suburban Nijmegen. Exploring the extensive beer menu and, even sometimes, discussing the frontiers of quantum physics.
What a wonderful culture that, in a simple local bar (not a brash and noisy nightclub, just a regular local Dutch pub), you can enjoy a Trappist beer for breakfast. Bear in mind that at the time in England we had the stupid legacy of World War I whereby our pubs were forced to close at 10:30pm (fortunately no longer).
It goes without saying this experience was highly influential on me...
In my experiments I learned, for example, that Belgian beer comes in Dubbel and Tripel strengths - which means 6-7% and 9-10% respectively. I learned that glass etiquette is no small matter - to serve a beer in the wrong glass will get you 30-days in the local jail. I also learned that Triple's are best avoided if there's a full day of experiments planned the following day.
I carefully studied: Westmalle, La Trappe, Chimay, Achel as well as common-or-garden Belgium brews like Leffe. I found that my natural affinity was for the Dubbel's and preferably the blondes (no comment). But somehow one member of the "Belgian beer space" remained unreified: Orval

Ask me to describe ROC and I'll give it to you plain. But the fellows at Orval understand that serious beer is in the same league as fine wine and they have a poetic turn of phrase to describe it...
"The gustative sensations will gain in nuance depending on the age of the beer. Young beer is characterised by a bouquet of fresh hops, with a fruity note and pronounced bitterness, light on the palate and a less firm collar than a beer of six months. The latter will feature a bouquet consisting of a blend of fragrances of yeast and old-fashioned hop. The bitterness is more diffuse and the taste has moved to a slight touch of acidity accompanying yeast and caramel flavours"
...which I'm not going to argue with.
It may have been a late entry to my beer experience resource set, but its moved straight in at number one. Its a Blonde Dubbel at a "modest" 6.2% strength. If ever you get to Belgium try it, or better yet, go order one from an online importer - it'll be worth it.
† Notice how I carefully avoided the obvious and crass opportunity here? I leave it to you dear reader to fill in the resource-oriented-shaped space I subtly left.
* Experimental physics research actually has a direct relation to ROC. Measurement and Computation are the same side of the same coin. They are both the reification of representations from abstract resource sets. They are both about the art of shaping context so that requests for resources are reifiable.
In my Physics work the contextual boundary conditions were to position my semiconductor devices in the correct 1cm3 of space, to get things cold enough, and to apply a strong enough magnetic field; all before determining the state. The state, as it turned out, was crystalline electrons (a Wigner-solid). Well actually it was p-type semiconductor, so I was actually measuring crystalline holes. And since holes are not real, just "gaps", this was a solid of stuff that doesn't actually exist!
Now's not the time, but I have plenty more to discuss about Computation and Measurement and ROC at some later date.
Bizarre Coincidence
It is entirely coincidental that the NetKernel West 2011 conference is taking place in Fort Collins. I had absolutely no idea that Fort Collins is the craft micro-brew capital of the US. I was unaware that this is "beer central", or that there is a brewer called "New Belgium Brewing" located there. All entirely coincidental.
Of course, my mind was on higher things, planning the extensive NK/ROC programme for NKWest2011, Fort Collins, Colorado, USA, 12th-14th April. Did you know you can find out all about it and book your place today to avoid disappointment...
http://www.1060research.com/conference/NKWest2011/
I can categorically state that it would be entirely a matter of accidental circumstance if the higher-purpose of the consumption of ROC knowledge, should accidentally lead to the reification of knowledge of hop-oriented composite resource representations.
I hear the siren call of "research" again.
If you're affected by the Japan tragedy, our thoughts are with you. Take care.
Comments
Please feel free to comment on the NetKernel Forum
Follow on Twitter:
@pjr1060 for day-to-day NK/ROC updates
@netkernel for announcements
@tab1060 for the hard-core stuff
To subscribe for news and alerts
Join the NetKernel Portal to get news, announcements and extra features.
NetKernel will ROC your world
 |