|

NetKernel News Volume 2 Issue 4
November 12th 2010
What's new this week?
- Repository Updates
- Space Explorer
- Space Explorer Videos now in HD
- Production Memory Analysis: Heap Dump
- Resource Oriented Computing and Programming Languages
Catch up on last week's news here
Repository Updates
The following packages are available in both NKEE and NKSE repositories...
- coremeta 1.8.1
- fileset accessor renamed to improve consistency
- database-relational 1.8.1
- fix a threadsafely issue when getting pool state in explorer
- http-server 1.17.1
- document HTTP_CACHE_EXPIRES_DELTA_SECONDS
- module-standard 1.33.1
- fileset accessor renamed to improve consistency
- fix so that status tab is highlighted when selected
- Various updates to Space Explorer II (see below)
- nkse-dev-tools 1.25.1
- removed legacy redirect endpoint and moved to explorer
- system-core 0.19.1
- added indexing of references to representations in metadata model
Space Explorer
More polish was added to Space Explorer II
- entity icons added to navbar
- containing physical endpoint added to navbar for logical endpoints, prototypes and representations
- fix to enable viewing of module.xml inside jar modules
- book css used for embedded documentation
- new settings page allows configuration of which modules are considered libraries (this is used by the static structure diagram)
- improved static structure diagram template based on feedback
- new "Find Originating Physical Endpoint" tool for logical endpoints. This traces the delegation of an endpoint through to it's origin.
- new "References to Representation" tool for representations. This shows all logical endpoints which either return this representation or source it as an argument. (Currently most libraries are not fully defining this but they will be updated soon)
Space Explorer Videos now in HD
If you were quick off the mark last week and viewed the space explorer tour on Friday, you might like to know I found a way to get them uploaded to Youtube with HD resolution preserved...
- Space Explorer Tour - Part 1 - Using the Explorer to develop a new module 9:22
- Space Explorer Tour - Part 2 - Visualizing architectural relations (Throttle example) 8:23
- Space Explorer Tour - Part 3 - Inspecting transports to see high-level system structure 8:00
Recommend you view at 720p and fullscreen.
Production Memory Analysis: Heap Dump
We had some fun this week helping Sven and Frank at Edge Technologies tune-up a very heavily loaded SNMP telecoms monitoring system. One thing we needed to look at was the object graph in the heap to see where the memory was being consumed.
My usual approach is to use jmap since it can be run on a live production system with no set-up. The technique goes like this...
- Dump the memory using jmap
- Use scp to download the dump file from the server to your dev machine.
- Get a recent copy of Eclipse and use the memory analyzer tool. It lets you load up and inspect the heap dump to quickly find the dominant objects.
Unfortunately, for operational reasons it turned out that it was not possible to install jmap onto the live production machine - jmap is in the java/bin/ directory on an SDK but is not shipped with the JRE. However Frank Bodeke realized he could use the JVM's HotSpotDiagnosticMXBean and knocked up and hot-installed a "HeapDumper" accessor, which he kindly forwarded to us.
I thought that we could add this as a developer tool, but realised that you don't even need to do that. The scripting playpen in the developer tools panel is all you need...
http://localhost:1060/tools/scriptplaypen
Select "Groovy" as the scripting language, and exec this...
//Really Simple Heap Dumper import com.sun.management.HotSpotDiagnosticMXBean import java.lang.management.ManagementFactory import javax.management.MBeanServer dumpfile="heap.bin" server = ManagementFactory.getPlatformMBeanServer() hotspotMBean = ManagementFactory.newPlatformMXBeanProxy( server, "com.sun.management:type=HotSpotDiagnostic", HotSpotDiagnosticMXBean.class ); hotspotMBean.dumpHeap(dumpfile, true) context.createResponseFrom("Heap Dumped to $dumpfile")
heap.bin will be dumped to the install directory of your NK system (or specify a full path in dumpfile for another location). Remember to hit "Save" in playpen if you want to use the HeapDumper again.
Caveat: This is probably only good for a Sun JVM
Resource Oriented Computing and Programming Languages
Its about ten years since we created the first ROC language runtime resolved in a Resource Oriented Computing address space. For the record it was active:xslt.
You maybe don't get off on writing your code in XSLT but it is Turing complete - so it is fundamentally an equal with Groovy, Python, Javascript, Java, Clojure, Scala, Ruby, Beanshell or any of the other languages that you can program in on NetKernel today.
Here's something else to make you think. Apart from natural evolution of the black-box internal implementation, the XSLT runtime's logical ROC interface remains the same today as it was then; therefore given the same xml document "myDoc.xml" and the same transform "myTransform.xsl", then an ROC request for:
active:xslt+operator@myTransform.xsl+operand@myDoc.xml
gives you exactly the same xml resource today as it did then.
So the set of accessible resources computable with the XSLT runtime (and by Turing equivalence any other language) is very stable, even across generations of the NetKernel ROC system.
Its time to explore why ROC can make promises that deliver this kind of stability and, ultimately, examine how ROC sheds light on the nature of how we think about code, languages and computation.
Over the course of the next couple of newsletters I want to:
- Explain the role and concept of languages in ROC.
- Show how "Code State Transfer" shows the language runtime pattern to be just a special case of an arbitrary resource accessor.
- Describe the role of Turing complete language runtimes
- Explore why Turing equivalence is not necessary for an ROC system.
- Consider how ROC's extrinsic context can influence language design.
- Discuss the contextual trust boundary constraints required for "open computation" in an ROC space.

I hope that I'll be able to convince you that languages are second order. That as software engineers we can "step out of the 2D plane" of languages, programming and code. From a new "3D perspective", see that code is a means to an end, not the end itself.
Ultimately I hope to persuade you to look at the world as sets of information resources. Like Michelangelo releasing David from the marble block, information engineering is the art of applying context to release information.
I don't know if I'll be able to pull this off. But here goes...
Code State Transfer - Language Runtime Pattern
Firstly you have to forgive me. We have been living with ROC and language runtimes for a long time and we tend to take them for granted. Hence the ROC Basics tutorial I wrote...
http://docs.netkernel.org/book/view/book:tutorial:basics/doc:tutorial:basics:part5
where I pragmatically introduce language runtimes as script execution engines and just assume you'll "get a feel for it". Fortunately people do, but there's a lot of implicit knowledge assumed.
So lets go back to first principles and examine how the language runtime pattern works...
Lets consider an Endpoint EP1 that wishes to execute some code Code1 - for the sake of this example lets assume EP1 and Code1 are in the same address space SpaceA. Lets assume there is a library address space SpaceB that provides a service active:lang which is able to execute Code1; and SpaceB is imported into SpaceA via an import endpoint. The diagram below shows the spacial architecture...
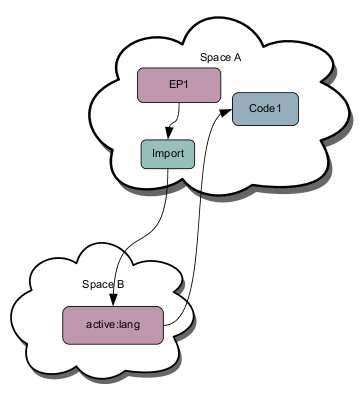
Lets assume that active:lang uses the conventional active URI (Butterfield, Perry, IETF Draft 2004) syntax for a language and supports an operator argument specifying the code (script) to execute.
Therefore to execute Code1, EP1 would issue a request...
active:lang+operator@Code1
This initiates the following sequence...
- The request is resolved via the import to SpaceB.
- SpaceB resolves the request to active:lang endpoint.
- The active:lang endpoint receives the request for evaluation
- active:lang issues a request for the operator argument, in this case Code1
- The request for Code1 is not resolved in SpaceB and is delegated back to the next nearest request scope SpaceA (we sometimes call this resolving "up the superstack", or in "the request scope").
- SpaceA resolves the request to the endpoint providing Code1 (we've not stated the nature of this endpoint, it might be a fileset, or could be dynamically generated. active:lang doesn't care).
- The Code1 representation is returned to active:lang whereupon it is evaluated.
- When Code1 has completed, active:lang returns the response computed by Code1.
- EP1 receives the computed representation resulting from the execution of Code1.
At face value this seems like a lot of work. But there's even more! To show the broad steps I deliberately missed out some of the background detail...
Compilation Transreption
Let's assume that SpaceA's Code1 endpoint provides a binary stream representation (not uncommon for code coming from a module on your file system). Let's also assume that active:lang is implemented to run against the JVM and the implementation executes JVM bytecode.
- When active:lang issues its request for the operator Code1 it indicates that it requires a LangByteCode representation (in spaceB lets assume there is a representation class called LangByteCode - a value object holding byte code of the given lang).
- When Code1 is returned to active:lang the kernel determines that Code1 is a binary stream.
- The kernel issues a TRANSREPT request to resolve an endpoint that can transrept binary streams to LangByteCode.
- SpaceB has a transreptor that compiles this language (quite naturally a runtime and its compiler transreptor are usually located in the same library address space)
- The compiler compiles (transrepts) Code1 to LangByteCode.
- The LangByteCode is returned to the language runtime for evaluation.
That's the whole story. Wow a lot goes on. Why the heck would you go to all this trouble just for EP1 to run Code1? Surely I'd be better off having a function inside EP1 that does the same job?
Return on Investment
Ah but that's to overlook even more detail... As the chain of requests were issued the relationships between the spaces, the endpoints and the resources were fully determined and all the state was cached.
So what happens the next time EP1 wants to execute Code1?
- The request is immediately issued to active:lang for evaluation (The resolution doesn't happen - it was cached in the resolution cache)
- active:lang requests Code1 which is instantly returned as LangByteCode from the representation cache.
- active:lang executes Code1 and returns the representation (more on that later).
Just as a HotSpot Java VirtualMachine JIT compiles bytecode to native code; NetKernel is "JIT compiling" both the code *and* the spacial context in which the evaluation of the code is occurring.
Because NetKernel/ROC discovers and accumulates optimized state, the effective runtime state of the system is to conceptually consider that the Code1 resource has been "state transferred" with minimum entropy to "active:lang" as shown in this diagram...
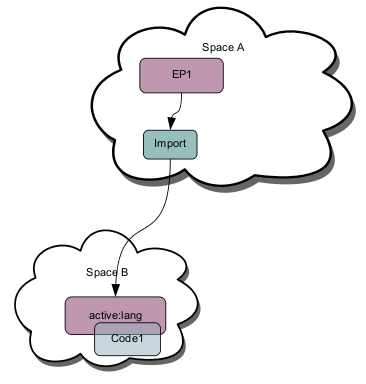
The computational cost of EP1 going extrinsically through the ROC address space to execute Code1 is, as near as damn it, no different to if it had a local hard-coded internal function (in real terms, the "abstraction cost" is two constant time map lookups).
The benefits are significant, just in physical terms (not dynamic state minimization - we'll cover that later).
- EP1 and Code1 are "dialectically decoupled" - they do not need to be written in the same language.
- Execution of Code1 automatically scales linearly with CPUs.
- Code1 can be executed asynchronously just by issuing the request with issueRequestAsync()
- EP1 can be "logically decoupled" from Code1 by simply introducing a mapping in SpaceA to, for example, have an alias like this...
myService -> active:lang+operator@Code1
- If we decide that Code1 is a critical performance hotspot and needs to be optimized and written in Java then it can be replaced with a Java accessor class with no change to EP1 (which may *not* be written in Java itself).
Where's the Code? I don't care its a resource
Now in this example we co-located Code1 with EP1 since it allows us to show a typical pattern for contextual application spaces. But Code1 is just a resource. What if I set up my spacial context so that Code1 was mapped to an http:// URI and we imported http-client library. Or Code1 was a data: URI - the identifier and representation are the same?
Equally we could have an endpoint co-located with the language runtime, a stateful address space to which we could SINK and SOURCE code representations. EP1 can request the execution of code located in the remote address space.
With ROC we have complete architectural freedom to partition state where it is computationally cheapest - this state partitioning invariably is a runtime consideration and has no bearing on the logical composition of a solution.
Which is why long-term system stability is invariant with respect to physical and architectural change. Or, to put it another way, it should be no surprise that 10-year old systems keep on running across generations of physical platform.
Summary
This has been a fairly dry step-by-step description of the language runtime pattern. In practice you never think about this - you just issue (or map) a request to your preferred language runtime and tell it what code to run. The detail is irrelevant to a solution developer.
Next time I'll talk about the relationship between function arguments, resources, languages and execution state.
Part 2: Imports and Extrinsic Functions
NetKernel West 2011 - Denver Area, April 2011
Its been two years since the last NetKernel conference, NK4 is finished and the NKEE release is out too. There are a ton of things to talk about. We don't have a precise space-time coordinate yet, but this much is certain: Denver Area USA, April 2011...
| NetKernel West 2011 | |
| Location: | Denver Area, USA |
| Time: | April 2011 |
Details on Venue, Dates, Logistics coming soon...
Have a great weekend.
Comments
Please feel free to comment on the NetKernel Forum
Follow on Twitter:
@pjr1060 for day-to-day NK/ROC updates
@netkernel for announcements
@tab1060 for the hard-core stuff
To subscribe for news and alerts
Join the NetKernel Portal to get news, announcements and extra features.
NetKernel will ROC your world
 |