|

NetKernel News Volume 2 Issue 41
August 12th 2011
What's new this week?
- Java Regression: Shutdown Lockup Status Report
- Repository Updates
- The tale of a series of unfortunate events
- (Not) On Java 7
- Java 5 Support - End of Life Heads Up, October 2011
Catch up on last week's news here
Java Regression: Shutdown Lockup Status Report
If you have experienced difficulties with a lock-up when shutting down/rebooting NetKernel. This was identified as a Java regression bug in Java 1.6.0_26 (full details are described below).
We have issued a workaround in the current NetKernel Standard and Enterprise distribution downloads. If you are experiencing this problem please download a fresh copy.
The workaround required the update of Jetty to version 7.x.x. This update was already available in the repos and would have been installed when doing a full system update from the Apposite repositories. If you do not experience the problem then you are already safe and have no need to do anything.
Alternatively, if you have a deployed system and don't want to update it you may also revert your JVM to 1.6.0_24 or earlier which does not have this bug.
Please let us know if you have any difficulties.
Repository Updates
No updates this week. Steady as you are.
The tale of a series of unfortunate events
Its the middle of the summer. Just the right time to take an extended weekend and actually spend some time with kids. Well that was the plan, but then all hell broke loose...
Not Lion To You
The first hint of trouble came in the middle of last week. We received one or two independent notices that "something weird is happening since I updated to OSX Lion". These weren't too specific but were not entirely surprising given Apple's strategic move to distance itself from Java (no longer maintaining their own JVM, making Java an option only on OSX).
Incidentally, it wasn't until I started playing with Android did Apple's moves on Java make sense. Apple very clearly sees the i-prod(uct)s as its gateway drugs and it wants developers to be on its Objective-C stack.
On the other hand, Android is fundamentally a pretty complete Java stack - if you know Java its a smooth transition to write for Android.
The mobile computing client is the industry's key battleground (just look at the patent wars around this). Therefore strategically it would make sense (to Apple) that Java is no longer a smooth default option on OSX. Instead it is gradually becoming higher-friction. So we can speculate the thinking will go: Diminish Java, indirectly diminish Android.
So hearing that "Lion is being weird with Java" was not entirely surprising.
Some internets more equal than others
By the end of last week, this ripple on the pond was "something to investigate" but hadn't triggered any major alarm bells. So I packed up the family and headed off for the planned long-weekend. Safe in the knowledge that the fort was being manned back at base and, anyway, I now had a 24/7 linux box in my pocket, 3G internet and WiFi...
On Saturday morning there was a note from Tom "Thermodynamics" Hicks (as he is now known after the conference) saying he'd had trouble with an update to the lang-groovy 1.9.1 package. Weird...
By this time I was up at my folks house on their WiFi network. I downloaded a clean NK and tried to reproduce. Hmmm... The package was downloading but failing to validate against its repository signature. I wonder if its been corrupted somehow?
OK all that was required was a quick rsync -nvirc to check that the mirror repository was identical with the master... Problem. SSH rsync timed out immediately. I couldn't ssh to the Apposite server.
An hour of trial and error followed. No matter what I did I couldn't use SSH on the borrowed WiFi. Clearly my parent's ISP is blocking "non-essential" ports!
OK plan B, lets use the Android phone's 3G and the excellent capability of android 3.3.x to turn its WiFi into an access point to bridge to the 3G/GSM internet. An Android phone gives you an Access Point anywhere!
This worked great. Simple to set up. Laptop connects to Phone's WiFi network and then to cell network. We're all set... Problem. My folks live in a cellphone blackspot. No 3G. Almost no GSM.
I just managed to do an rsync dry-run and see that indeed the lang-groovy package was not showing the right checksum and would need resynching from the master. But there was no way I could do it on the 30kbps GSM connection. OK, time to find a real network...
You know how in the old days neighbours used to knock each other's doors to "borrow" a cup of sugar? Well the modern day equivalent is to go round and borrow the password to their WiFi network. Two minutes later and lang-groovy was rsynched and the package was installing properly. OK problem solved. We can relax - its the weekend...
Inexcusable First Boot Lockup
On Saturday afternoon, we received a brief note from Joe Devon an independent architect working on some seriously cool and high-profile systems in the LA area. The note said something along the lines of "Hey I've set aside this weekend to play with NK, is it usual that NK locks up when rebooting after doing a repo synchronization? I've killed it manually and rebooted and its now working".
WHAT THE?!!!!!!!
This was a bad sign. A very bad sign. This needed some real investigation. I'd just done a full install/sync that very morning to test Tom's issue. NK was working fine on my machine but clearly something bad was happening. By coincidence Joe was on OSX - but not Lion.
At this point, my loyalties were split and I had to assist with preparation for a major family event but Tony and the home team were digging into it...
[If you're not squeemish or religiously/culturally sensitive, here's a picture of our hog roast preparations - it turns out that preparing a Hog is quite a lot of work and requires a lot of manpower. My family live in Yorkshire and have ties with farming. This pig was one my brother knew personally. She was called "Tulip" and after 12 hours roasting, was delicious.]
{kind=link}
For Umbridge
Sunday morning. Another note, "Hey did you know your nk4um is offline showing..."
org.postgresql.util.PSQLException FATAL: sorry, too many clients already
No way! How can this be? Its been running flawlessly for a couple of months since we migrated from the old forums (as it turned out this was the problem). By the time I saw the note, the home team had fixed it by kicking the forum's RDBMS postgres server. But still another bad user experience.
OK two things that now needed detailed investigation.
I predict a riot
By this point my weekend away had been busier than my days in the office. At some point mid-Sunday I glanced at the BBC news. WTF!!! Its not just me, the whole world has gone mad. The world markets were in freefall and in London there was rioting and complete civil meltdown.
Fortunately it was a very small number of people. But just take a look at this outrageous fragmentation of society to see how quickly it can all go wrong...
[Joking aside, this thoughtful and very articulate article by Russell Brand (don't let that put you off) seems to encapsulate the situation very well.]
Hunting the Higgs Lockup
Meanwhile the main event I'd travelled for was on Sunday afternoon/evening. So I left Tony to dig into the hanging shutdown problem - I had a pig to roast.
As you'd expect the first place you look is in the places you're responsible for. So he checked and rechecked the kernel the shutdown hooks etc etc. But on our various development, test and production systems we could not reproduce the problem!
On Monday Tony started to make progress. Having eliminated the things we know about, we started to look at the known unknowns (Donald Rumsfeld where are you now?). We had a hint from the error report that it was Jetty not shutting down and perhaps due to NIO locking up. With this and our investigations it was suggesting that it was nothing directly related to NK at all.
Sometime during Monday/Tuesday Tony managed to isolate that this was only occurring on Java 1.6.0_26. No wonder we'd not seen this - we don't like going to production on bleeding edge JVM releases (after this story you'll understand why!). It was true. On Java 1.6.0_26, Jetty 6.1.x was dying with maxed out threads when requested to shutdown. When connected with a remote debugger it looked like the java NIO code.
By Tuesday evening Tony had determined that this issue was more isolated still. It was only present with Java 1.6.0_26 and Jetty 6.1.x. Switching to Jetty 7.x.x (which is provided in the latest http-server package in the repositories) it did not occur even on Java 1.6.0_26. Nor did it occur if you reverted Java back to 1.6.0_24 (our production JVM). At this point we knew enough about the issue to send out a detailed alert to the mailing list and forums (which were still running!).
Most importantly, it was likely that the issue would be most significant to new users downloading NK and running it out of the box to sync and pull the updates from the repository. (Not a good first experience!) But the majority of long-standing customers would have been on the Jetty 7.x.x-based http-server module for more than six months - so would unlikely have seen this at all. We could breathe a little easier.
Wednesday morning I travelled back to base and was in the office early. With network and full set of "tools" we quickly patched the NK distribution images to use the latest Jetty 7.x.x library. Tested on as many JVM's as we have. Pushing the distro release out to our mirrors within an hour. Phew we had stemmed the tide. Or so we thought...
The Big One
 As it turned out, these were just pre-shocks in anticipation of the big-one. On Wednesday evening at 5pm my email stopped working.
As it turned out, these were just pre-shocks in anticipation of the big-one. On Wednesday evening at 5pm my email stopped working.
Usually the first instinct with such an event is to check the DSL - but I could reach the web. But even worse, I could not connect to any of our sites/services. So I tried pinging the servers. Nothing. Oh-oh.
Next I tried to ssh into one of our physical hosts (running multiple KVM virtualized servers). No answer.
Time to get hold of our hosting provider, RimuHosting, support team - but their website is timing out too. I try pinging their server - dead, just like ours!! WTF?
It was starting to look serious and there was no immediately obvious channel to get hold of them. At around this point Mr Brian Sletten popped up on Skype. "Hey did you know Rimu are down?", "Er yeah sort of, how'd you know?", "Its a major power outage.". Now, Brian is well connected, but his knowledge of the cause and nature of the outage at our hosting provider was a little spooky. "How do you know?". "Oh my servers are on Rimu also and I used this thing called Twitter to search @rimuhosting". "Doh!".
What followed was an evening of educational frustration...
Hours 0-3
Initially information was very very thin on the ground. Lots of voices shouting about service and few voices echoing back any concrete information. Over the course of the first 2-3 hours it emerged that this was no small failure. The entire Dallas Colo4 facility was toast. This is a premium, class-A data centre with double redundant power supplies, generators and UPS. Something really really bad was going down.
What lessons can be learned from this first phase of the disaster response. Well it really pays to get onto twitter and other social media to provide as much information as available. Even non-information is good to send "We still have no news but will post another update in 15 minutes" is reassuring that at least someone is on the case.
It was very apparent that the Colo4 team were in a terrible panic and no-one had the wits to make simple statements of fact. We actually use Rimuhosting as our provider for dedicated servers hosted at Colo4. Even though it was the middle of the night one of their guys kept us updated by posting near-continuous updates on Twitter.
In case you were trying to access our services during this time. We were also posting twitter alerts on both the @pjr1060 and @netkernel accounts. If ever in future you think we're offline and shouldn't be then make sure to check these for real-time updates.
Hour 4 - Some Information
Sometime around the 4-hour mark we started to find out more about what was going on. It was reported that the ATS had burned out. The automatic transfer switch (ATS) is like a circuit-breaker and triggers on a mains outage to bring up the standby generators with in-fill from UPS. With this burned out there was no supply from any source!
I'm pretty comfortable with electrical circuits but you don't go messing with 3-phase mains voltage on a whim. This was clearly going to take some serious time. Here's a diagram of the double-redundant power supply system at the data center with the ATS failure marked with a big red cross...
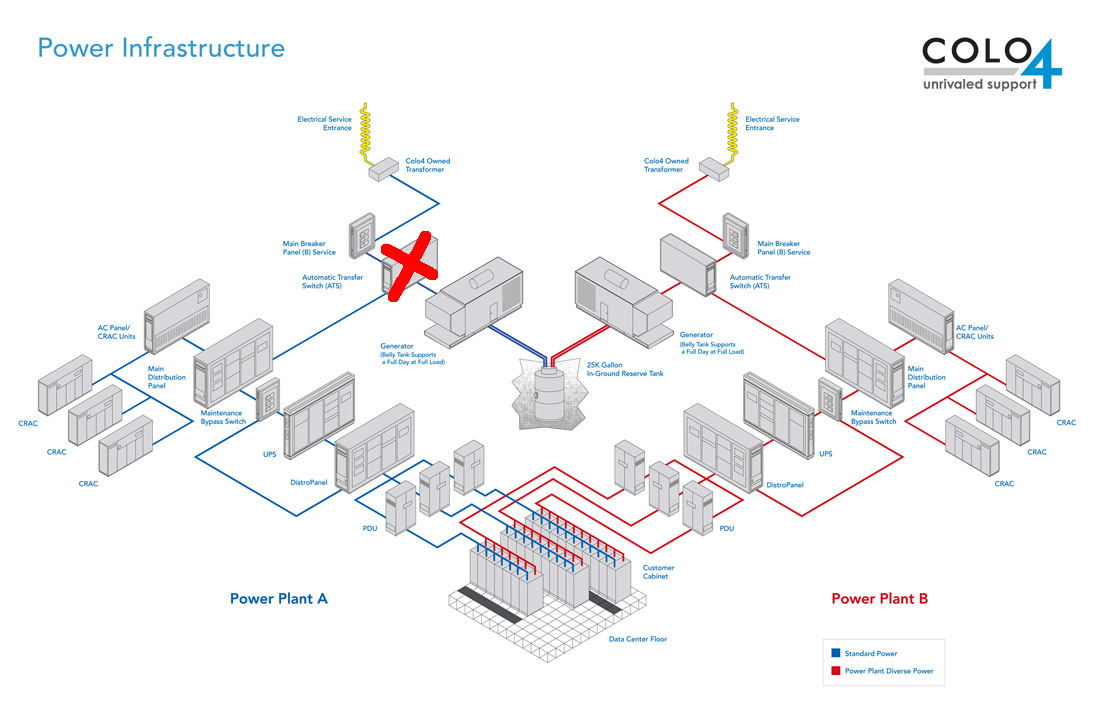
Hour 12 - We're Back
With this knowledge the question that remained was how could this take out the data center? There's a secondary B-circuit that should have been unaffected? The answer to this only emerged after the 12-hour mark - when the ATS had been replaced with a standby unit and power began to go back on.
We were able to get to our servers to discover that indeed they had had no interruption of supply! But we were taken "off-net" due to the failure of switches and routers.
In the cold light of dawn we discovered this post from Colo4...
"Colo4 does have A/B power for our routing gear. We identified one switch that was connected to A only which was a mistake. It was quickly corrected earlier today but did affect service for a few customers."
Huh. Thanks.
Lessons

So what are the lessons? Well, fundamentally bad things do happen - even very low probability things.
Its pays to have a way to communicate en-mass with the people that rely on you. The first job is to publicise how you are talking to people and the word will spread naturally.
Always tell the truth and don't try to do marketing while fighting a fire. We know its serious our services are down. Even if no solution has yet been identified - say that.
As soon as a solution is identified - describe it and explain the possible scenarios. Even if this means you have to admit it may not succeed.
Finally, since entropy will always get you in the end, learn from the event. I know I'd rather be hosted in a data centre that has been hardened by a real event.
So what does this tell us about "The Cloud". Well it will go down from time to time. If you're using cloud services be aware of your dependency.
It may be the risk of loss of service is a price you can afford - remember its not the duration of the loss of service that costs you, its the value of loss of business during that time. You might be able to afford to loose an hour's business, can you afford a whole day? Or two days?
What is surely needed is for insurance companies to offer policies on cloud service provision. I can insure my business against theft, fire, flood etc. "Loss of cloud" is just a line-item and it can be measured and underwritten.
If I wasn't already busy trying to change the world - as a serial entrepreneur, I'd surely be considering doing a cloud-insurance business. I'd probably call it "Silver-Lining Insurance Inc" (I'm a loss to the world of marketing, a real loss).
Incidentally, the Rimuhosting guys stood up valiantly. The entire thing was beyond their immediate control but they posted good information and worked tirelessly to boot and validate their users once power came back. Here's their post-crisis statement...
https://rimuhosting.com/maintenance.jsp?server_maint_oid=181086391
And in case you think it doesn't happen to everyone. Well by coincidence, earlier this week Amazon EC2 had its second full outage of the year...
http://techcrunch.com/2011/08/08/amazon-ec2-outage/
Postendum
If you're worried about nk4um - you can relax. After a little investigation it turned out that the Liquibase accessors were not closing their Postgres JDBC connection. Ordinarily this would have been sorted out in the wash - but unfortunately NK stays up without reboots for long periods. Eventually the connections accumulated to the point where they exceeded the safety config level set on our Postgres server and threw the too many connections exception.
No finger pointing - its a recent release and our production forum gets absolutely hammered 24/7 by a combination of bots, real users and people coming in at right-angles from search results, so our statistical load profile is a little pathological. Needless to say we've worked with Chris to sort out a simple fix to the Liquibase accessors and the server is now rock solid for the next 5 years, like our previous NK3 forum ;-)
(Not) On Java 7
The investigation into the Java 1.6.0_26 regression led us to seriously investigate the viability of Java 7.0.0. We had not previously considered it as a viable option since its inauspicious release - you may have heard that it was shipped with known serious show-stopper bugs...
http://drdobbs.com/java/231300060
In our cursory testing we have immediately discovered that the Lucene indexing of the NK system is vulnerable to the known Lucene J7 JIT bug which can/will crash your JVM.
We strongly recommend that you do not attempt to use Java 7 until at least update 2 - which will have fixes for the most critical JIT compiler bugs. As with all JVM updates, it is very important to do testing in staging on the proposed JVM update before committing to use it on production servers.
Java 5 Support - End of Life Heads Up, October 2011
Back in February we reported on how it was becoming increasingly difficult to maintain NK on Java 5 since Java 5 reached end-of-life in October 2009.
Having supported NK on Java 5 for two years after Sun ended support of Java 5, we must now announce that: Backwards support of NetKernel 4 on Java 5 will reach end of life in October 2011.
We have a planned platform refresh in the works and we will coordinate the release of this refresh with the end-of-life of Java 5 support.
Recently we have had reports of the possibility of classpath library issues when trying to use xml-core for the javax.xml.stream package. This package is now included with Java 6 whilst xml-core currently provides a transitional impl for Java 5. After the refresh/EOL transition we will remove the transitional javax.xml.stream package from xml-core.
If you are using this library and wish to test in advance, you can simply edit the urn.org.netkernel.xml.core.x.x.x module and remove stax-1.2.0.jar and stax-api-1.0.jar from the lib/ directory. Your system will then use the Java 6 API and implementation library.
Please let us know if you have concerns or need assistance with planning/testing for this transition.
Belgium Bootcamp Update
We now have a provisional date fixed for the 27th October. We also have a very generous offer of a venue to host the event. More details to follow.
Please, if you expressed interest, can you confirm that the 27th is good for you. We planned to put up the registration site this week - but as you see we were otherwise engaged.
Have a great weekend,
Comments
Please feel free to comment on the NetKernel Forum
Follow on Twitter:
@pjr1060 for day-to-day NK/ROC updates
@netkernel for announcements
@tab1060 for the hard-core stuff
To subscribe for news and alerts
Join the NetKernel Portal to get news, announcements and extra features.
NetKernel will ROC your world
 |